Beyond Buzzwords: A Closer Look at Data Job Descriptions in Belgium
This post was co-written with Cesar Legendre of Prophecy Labs
Exasperated Data Scientists Applying for Jobs. Credit: Jesse Blum via Midjourney

Introduction
Has “data science” peaked? It’s an intriguing question, with strong arguments for and against this provocative proposition. On the one hand, deep learning has recently captivated popular attention, with amazing innovations in text (e.g. large language models such as Chat-GPT) and image generation (e.g. services such as DALL-E and Midjourney, the rise of deepfakes in the political sphere, etc.) promising to disrupt many professions from screenwriting to advertising to customer service. On the other hand, many organizations struggle in the data/AI space, facing problems ranging from basic (e.g. collection and storage of basic transactional data) to sophisticated (e.g. struggles with migration to the cloud, deployment of data solutions into existing business or client-facing applications), not to mention the ever-present talent problem (with the relative lack of qualified professionals and a workforce that is not in all cases ready for the digital disruption that data has the potential to deliver). It appears as though progress in developing and adopting data solutions is bifurcated - a relative few companies are adopting advanced analytics solutions to great success, while many are taking their first steps and struggling to fully adopt the promise of AI.
In this landscape, what does the job market for data professionals look like in 2023? Our analysis of European data science job ads from 2022 suggested that European companies looking for data talent placed a great deal of importance on technological skills, to the detriment of softer skills such as empathy and communication, which are important in a larger organizational context.
This blog post presents an update of our 2022 analysis of European data job advertisements, with an examination of a larger portfolio of roles, in order to understand the rapidly-evolving labor market and data role landscape. In contrast to last year’s analysis, we focus here exclusively on the Belgian job market, as this is the country where both authors live and work.
The results revealed a great deal about the data job market in 2023 in Belgium. Specifically, business analyst, devops engineer, and data engineers were the most in-demand job titles, recruitment agencies and consultancies were the main posters of data job advertisements, and about half of the posted jobs were in smaller-sized companies. Three years after the start of the COVID pandemic, Belgian employers expect data employees to work from the office at least some of the time. As was the case last year, the most in-demand data tools are Python and SQL, and each role within the data space is associated with a distinct collection of tools that sets each role apart from the others. In contrast to last year’s analysis, employers are placing increasing importance on soft skills such as communication and collaboration. Finally, our data suggest that employers frequently re-post the same job description multiple times (presumably to remain at the top of the “new jobs” list), and use emojis to appeal to a younger, tech-savvy demographic.
For all of the details, read on below!
Data
Our primary data source consists of 25,965 unique job descriptions scraped from a major online job board. Specifically, we scraped all jobs that were returned with the query “data scientist” from January to April 2023. For each job description, we extracted the following pieces of information: the job title, the job description text, the posting company name, company size, company sector and the way of working (e.g. office, remote, or hybrid).
What Roles are Most In Demand?
We first examined which roles were most sought-after. The most-frequent job titles for the scraped job advertisements (searching explicitly for “data scientist”) was software developer, followed by project manager. This is quite interesting, and perhaps captures important areas of overlap: software tools such as Python, CI/CD, are common between the data scientist and software developer roles, while the agile methodology is common between the data scientist and project manager roles.
Figure 1: Most Frequent Job Titles Returned with the Query “Data Scientist”
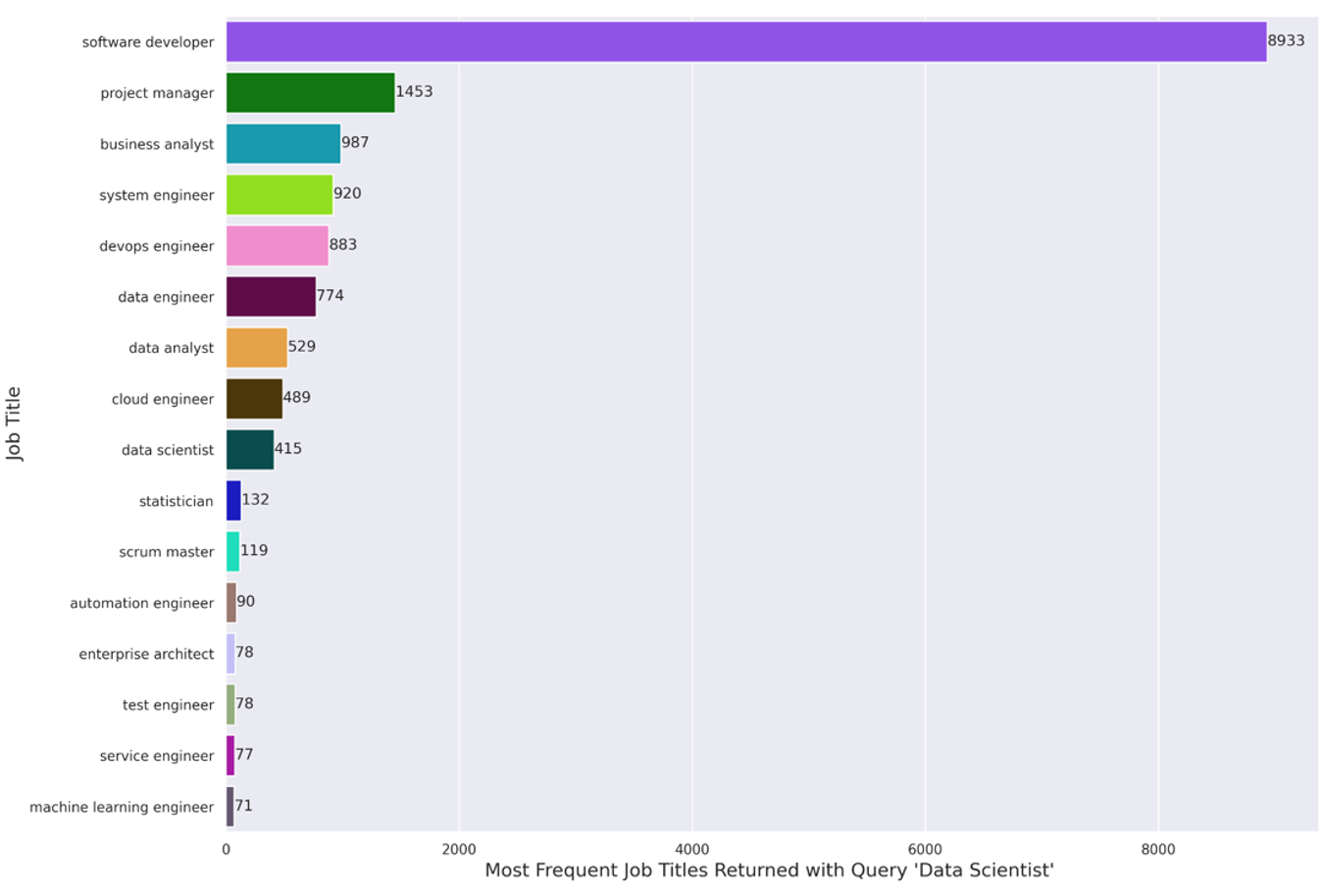
Data scientist roles, meanwhile, were only the 8th most-common job title for searches for data scientist jobs!
A Focus on Data Roles
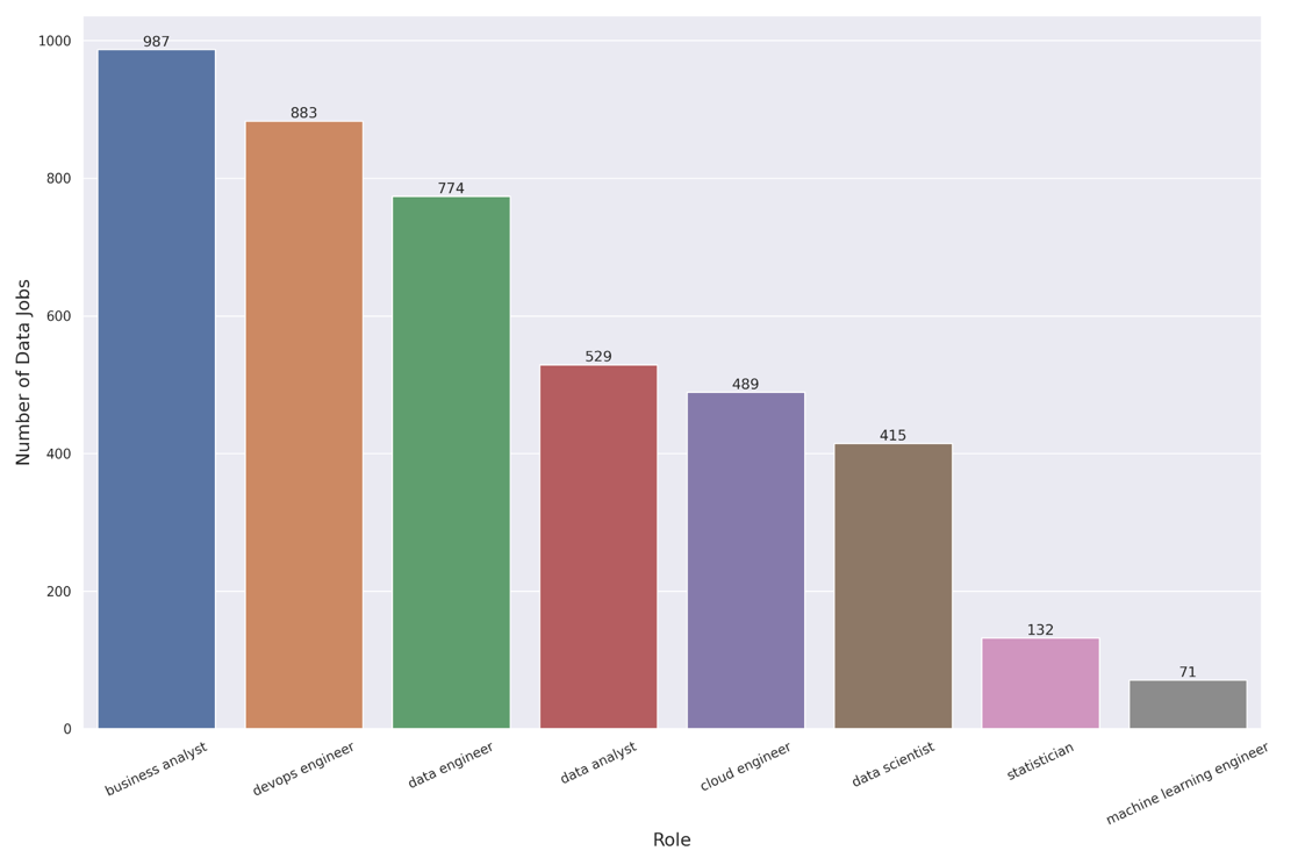
For the remainder of this blog post, we will focus exclusively on data roles (N = 4280), specifically on the following job titles:
- business analyst
- devops engineer
- data engineer
- data analyst
- cloud engineer
- data scientist
- statistician
- machine learning engineer
Figure 2: Number of Data Jobs Per Role
Who Is Looking for Data Talent?
Company Sector
In Belgium, by far the largest sector recruiting for data profiles is the staffing and recruitment sector. Anyone who has spent any time in the data space has surely dealt with recruiters! In Belgium, it appears that many companies feel unable to recruit data profiles on their own (or they’re simply looking for freelancers), and so many jobs are advertised and filled by recruitment agencies.
Figure 3: Number of Data Jobs Per Sector
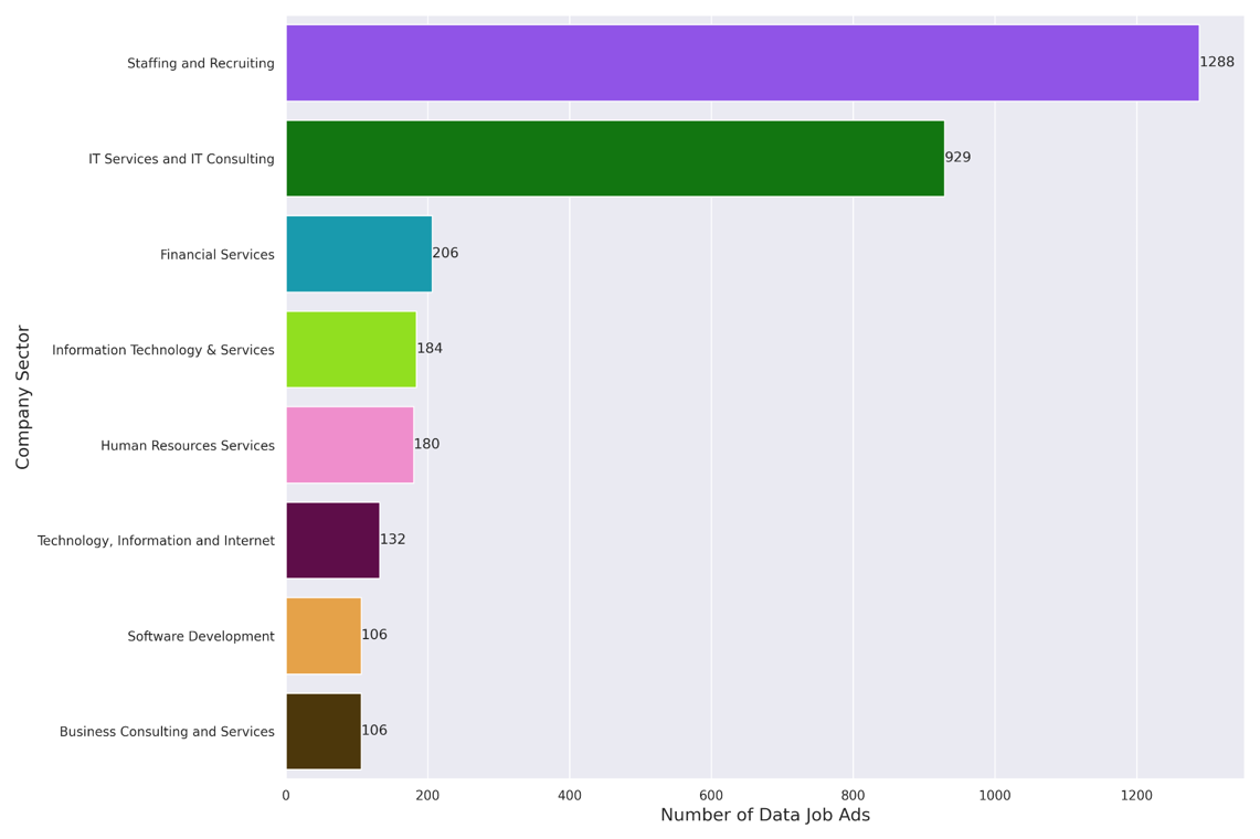
The other major sector represented in the above graph is the services / consulting sector (e.g. financial services, IT services, etc.). In Belgium, in 2023, this is where many of the jobs are. Some of these jobs are of course with the big consulting companies, but others are in small tech/data consultancies, often but not always specialized in a specific sector (e.g. finance).
Company Size
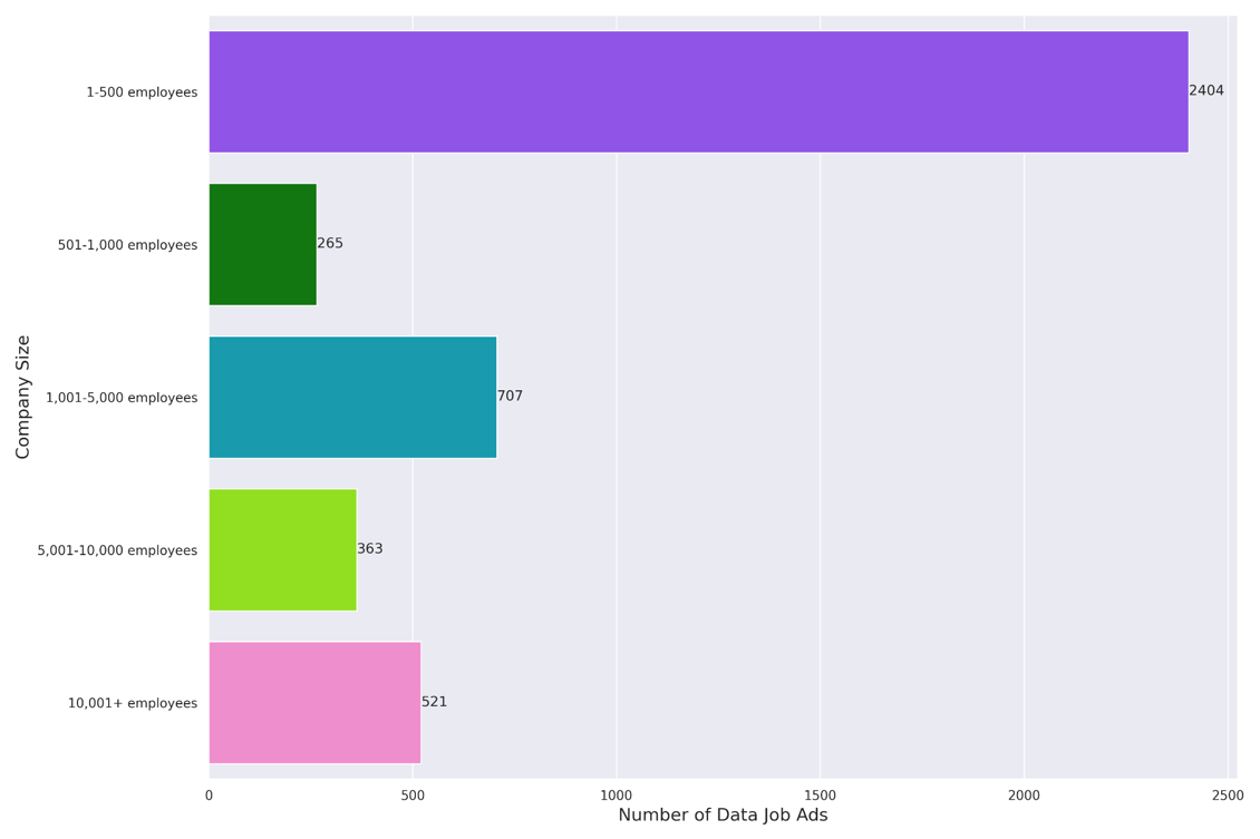
As was the case last year, most data jobs are at smaller organizations - in between 1-500 employees. Many of these companies are smaller startups or consultancies with a digital / tech flavor baked in from the very beginning.
Figure 4: Number of Data Jobs Per Company Size
Three Years Since COVID Began - Are Data Profiles Expected Back in the Office?
The COVID pandemic radically changed the way that many people in the data space work. While the pre-COVID norm in Belgium placed a great deal of importance on being physically present at the office, when the pandemic began, many companies adopted remote working practices overnight.
Three years after the pandemic began, what are the expectations in terms of ways of working for data profiles? According to our data, the most frequent way-of-working is hybrid, followed closely by on-site roles, with remote appearing least frequently.
Figure 5: Number of Data Jobs Per “Way of Working”
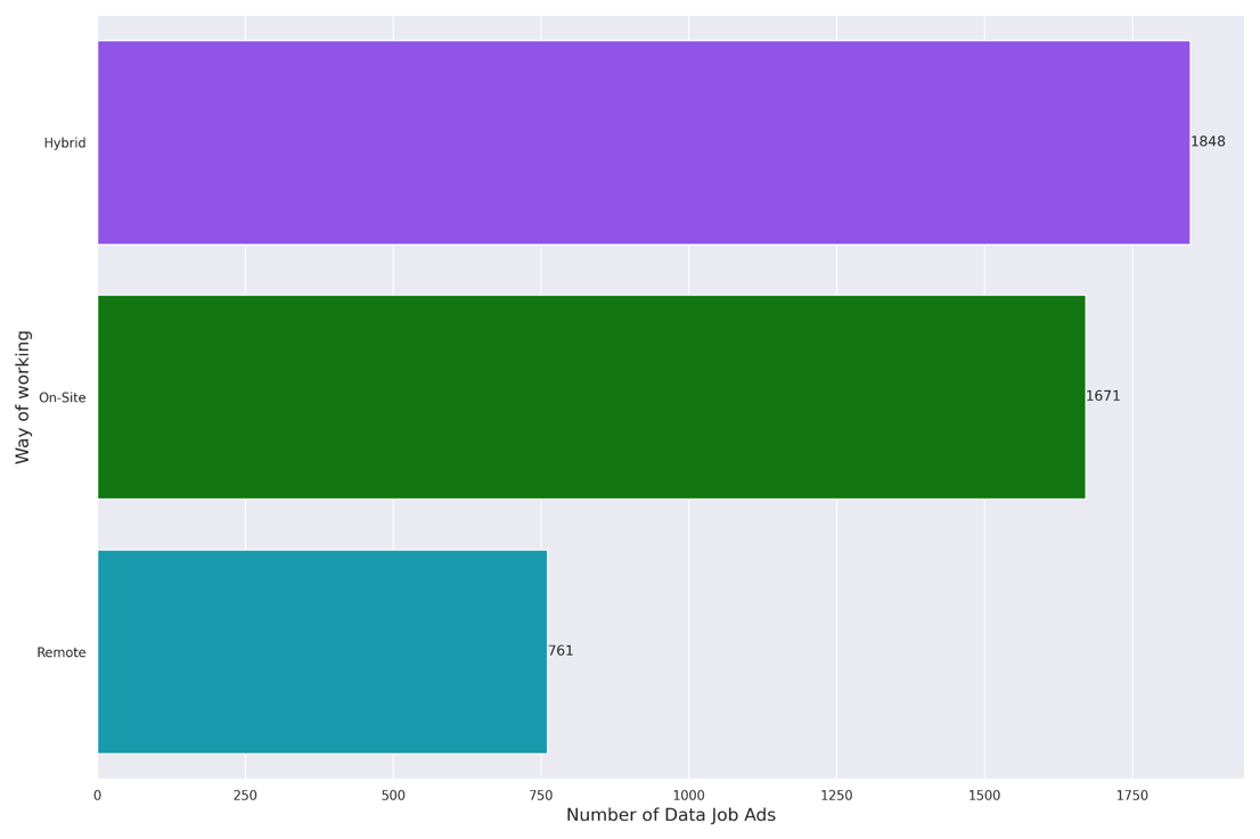
It therefore appears that companies in Belgium are reluctant to fully embrace remote working for data roles in 2023. It’s clear that, for many jobs, we’re not going back to the pre-pandemic world just yet, as evidenced by the large number of hybrid roles. But given the relatively small share of remote jobs, it is clear that Belgian organizations expect data employees to be on-site at least some of the time.
What Are Employers Looking For?
Unlike last year’s analysis, the current data do not contain employer-provided keywords of the desired skills for each job description. Therefore, we used openAI) models to analyze each job description and return the tools and skills mentioned in the job description texts.
To accomplish this task, we relied on state-of-the-art language models like GPT-Turbo-3.5 (May 2023 version) and GPT4, accessed via the official APIs. Coupled with prompt engineering techniques, these models enabled efficient and accurate extraction of the desired information from the job description texts.
The LLMs (Large Language Models) were able to extract the tools (python, kubernetes, etc.) from the texts relatively easily, as data tools are typically referred to by their unique names. However, the extraction of skills presents a bit more of a challenge. The language used to describe the same skill can vary between sectors or even individual job listings. For instance, the skill of ‘time management’ could be described in several ways, including ‘time organization’ and ‘efficiency in scheduling’. The LLM skill-extraction analysis therefore gave us a long list of skills that contained many terms that embodied the same concept, but described in different words.
To make this list more manageable, we turned to sentence embeddings, using the text-embedding-ada-002 model. By grouping together skills with a high level of similarity (i.e. cosine similarity of 0.95 or above), we were able to aggregate the long list of separate skills (e.g. ‘time organization’ and ‘efficiency in scheduling’) into a fewer number of higher-level categories (e.g. ‘time management’) that captured the essence of the underlying skill.
Tools
Despite the fact that the data science toolkit is constantly evolving, the top two tools are the same as last year, the programming languages Python and SQL. These are both undeniably important for most data science jobs, and are joined on the list by other programming languages like c# and JavaScript.
Figure 6: Top 25 Tools for Data Jobs
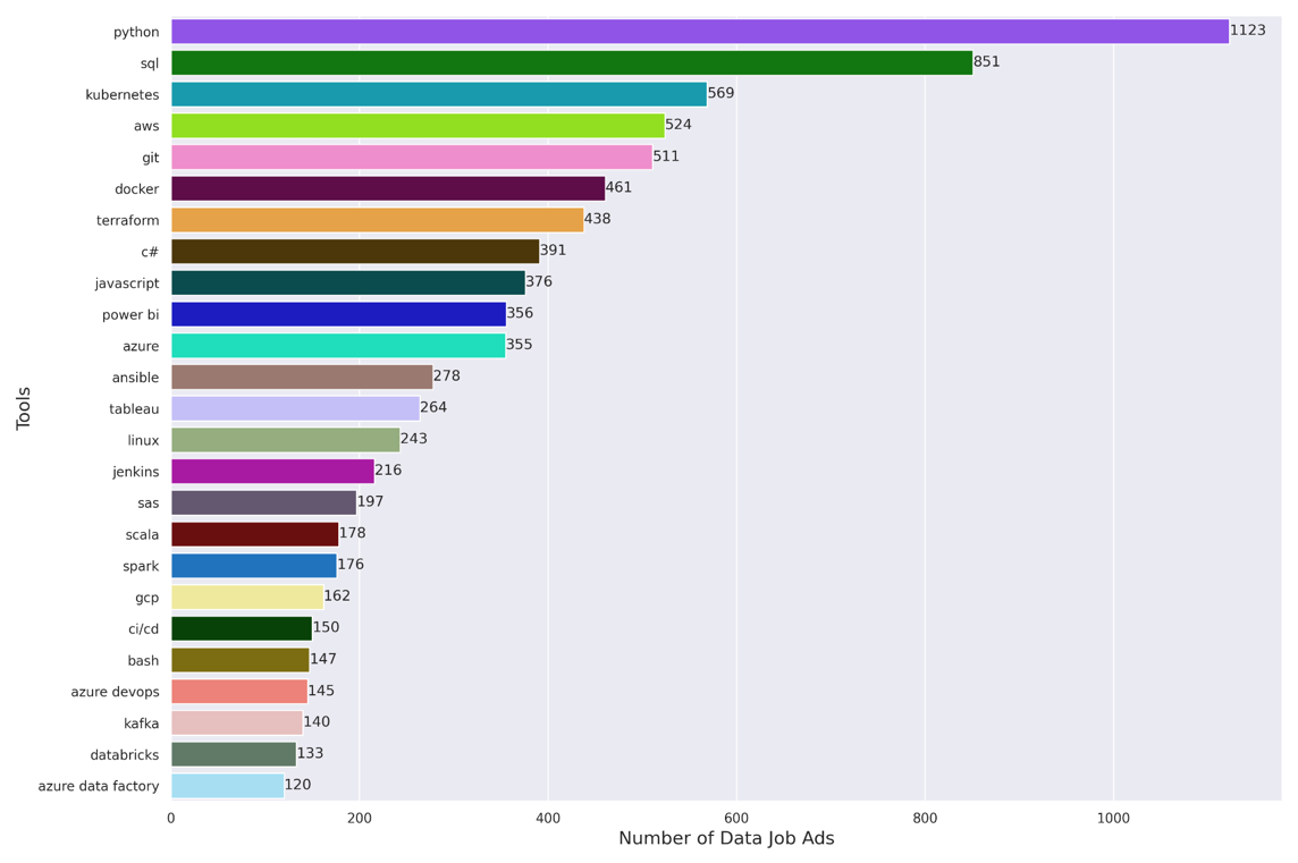
We see many tools related to the cloud, such as AWS, Azure, GCP, Kubernetes, Terraform, and Ansible. Increasingly, it appears, data science work is taking place in cloud-based systems, making experience with cloud platforms a valuable asset.
Unsurprisingly, given the link between data science and software, we see a number of software development tools in the list, such as git, CI/CD, bash, and Jenkins.
Data science is a large universe, and one aspect involves data visualization. This aspect is represented in the list with the most popular BI tools, Power BI and Tableau.
Finally, we see a number of tools based on the previously en vogue buzzword “big data”: Scala, Spark, Databricks, and Kafka.
Skills
When examining the most frequently-mentioned skills in the data job advertisements, we see a number of different themes emerging.
Figure 7: Top 25 Skills for Data Jobs
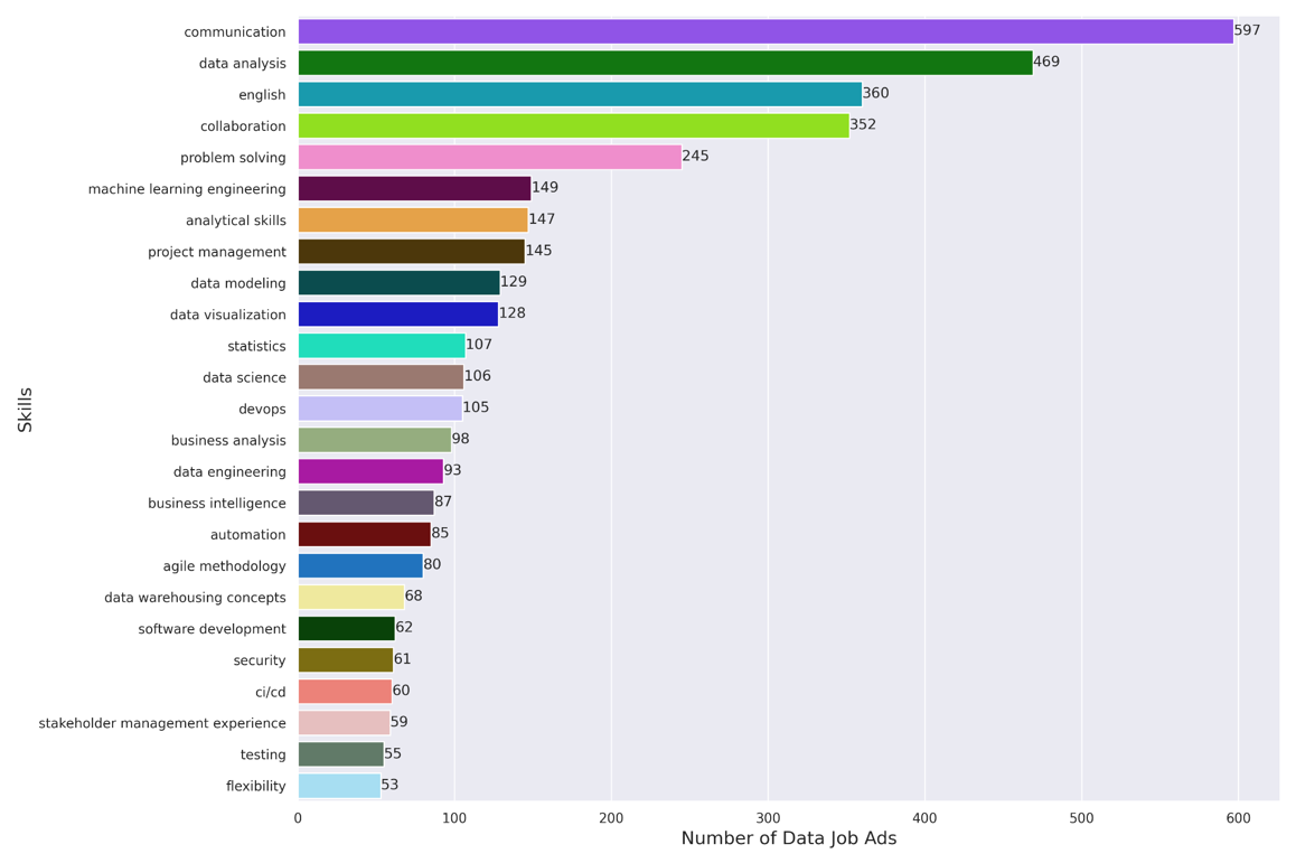
In contrast to last year, we see a number of “soft” skills such as communication, collaboration, and stakeholder management. In our view, these skills are fundamental to getting data projects done, and we are encouraged that the job advertisements increasingly mention this critical skill set.
We also see a number of data-related skills, such as analysis, visualization, ML engineering, and statistics. These skills get at the analysis, interpretation, and modeling of data, which are all core tasks in the data science role.
Interestingly, and importantly given that data science is a role that exists to serve overall business needs, we see a number of what we term “general business skills” such as problem solving, project management, and business analysis.
Finally, we see a number of skills related to software development such as devops, automation, security, and CI/CD.
Clustering Roles by Tools
In order to understand how the roles (e.g. data scientist, data analyst, etc.) differ by the requested tools, we made the below clustermap. We first calculated the percentage of job ads per role that contained each tool, filtering on tools that appeared in more than 50 job ads. These percentages were converted to z-scores per tool, such that higher numbers indicate that a given tool was mentioned more often for a given role compared to the others. This final matrix was then passed to the cluster map algorithm, which performs a simultaneous clustering of both the job roles and of the mentioned tools.
In this map, lighter colors indicate higher prevalence of a given tool for a given role compared to the others, while darker colors indicate a lower prevalence of a given tool for a given role compared to the others.
This analysis gives a good overview of the differences in employer expectations in regards to tools for the different data roles.
Figure 8: Clustering of Tools and Roles
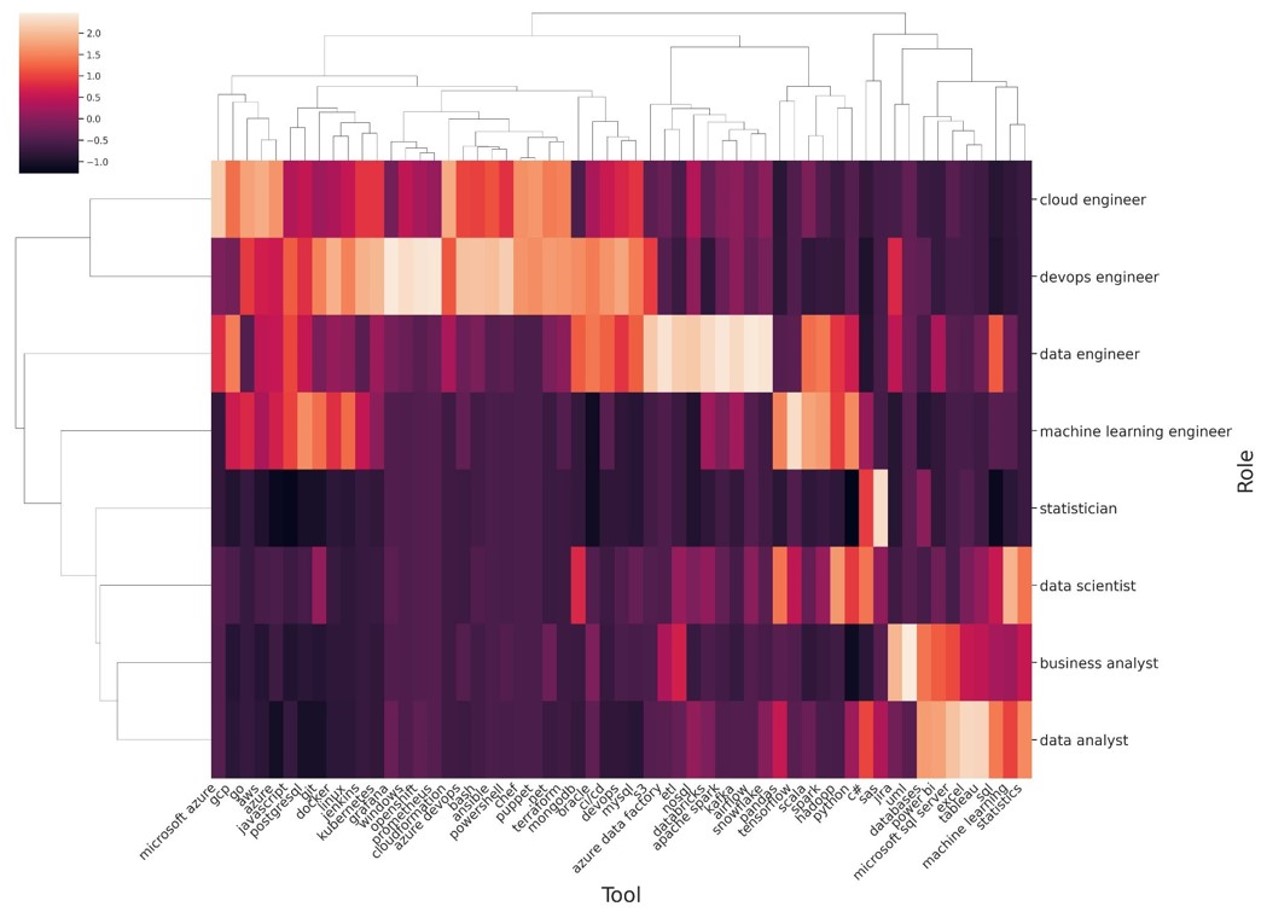
Cloud engineers are expected to know about cloud platforms (e.g. Azure, Google Cloud Platform and AWS), devops engineers are expected to know about deploying data solutions (e.g. Chef, Puppet) and infra as code (e.g. Ansible), while data engineers are expected to know about tools that are required for building data pipelines (e.g. ETL, Spark, Kafka, etc.). ML engineers are expected to know about deep learning (e.g. Tensorflow) and big data (e.g. Scala, Spark, Hadoop), while statisticians are expected to know SAS (but not Python, according to the graph!), and data scientists are expected to understand machine learning and statistics with Python. Finally, business analysts are expected to master tools to design data flows (e.g. UML) and dashboards (e.g. Power BI), while data analysts are expected to know tools that allow them to build dashboards (e.g. Tableau, Power BI).
One of the new up-and-coming data roles is the devops engineer. According to this analysis, they manage cloud infrastructure (e.g. OpenShift, Ansible), take care of deployment, industrialization of a data solution and integration into business systems (e.g. Chef, Puppet). This job title appears to reflect a splitting of the “data engineer” profile, and is a sign of the market evolving. Employers seem to be realizing that one person can’t do everything that’s needed in order to develop and deploy data solutions! As a consequence, data engineers, in this analysis, seem to be expected just to work on the data pipelines, leaving behind the cloud and devops aspects that were in their scope last year.
What to Watch Out For?
The data and AI space is very hot right now, promising new technologies and possibilities that many employers do not fully understand. As such, it is filled with creative, ambitious people trying to do something new (bring business value through data), but also with opportunists trying to make a quick buck (both employers and job candidates can be guilty of this!).
In analyzing the 2023 data job descriptions, we noticed a couple of things that prospective job applicants should be aware of when navigating the data job market.
Duplicate Job Ads
One tendency is for employers to post the same job ad multiple times, often weekly, presumably to ensure that the job description is returned at the top of the list. We found that 25% of the jobs in our dataset were duplicated, and that this pattern occurred most frequently among jobs posted by recruitment agencies.
Trying to Impress the Cool Kids
Inspired by the iconic “How Do You Do, Fellow Kids?” meme, Steve Buscemi in the role of an old-style recruiter trying to convince young data scientists that a particular job description is ‘cool’ enough.

When looking to attract young talent, job posters often employ a variety of creative marketing techniques. These include using social media, sharing engaging videos, spreading relatable memes, and posting motivational quotes. However, the conventional format of job descriptions may limit their creative arsenal of techniques.
As a result, integrating non-verbal communication tools like emojis into these descriptions can be a strategic move to bring them to life, making them more dynamic and visually engaging. A money bag emoji 💰, for instance, could emphasize the salary aspect, while a globe emoji 🌎 might indicate a remote working opportunity. Emojis can also subtly hint at a company’s culture (a consistent use of emojis might suggest a more casual, friendly, or creative work environment).
Figure 9: Count of Data Job Descriptions With Different Number of Emojis
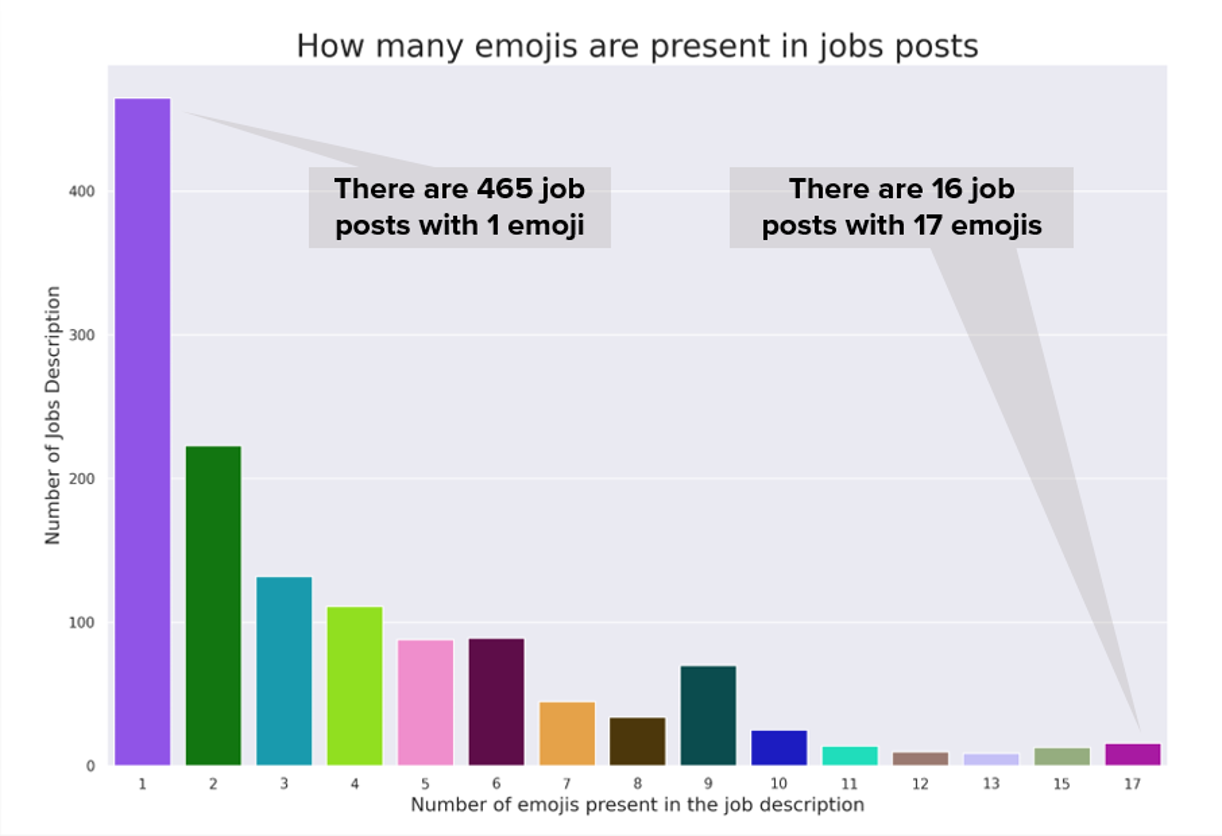
Our analysis reveals that 5.3% (1,376) of job advertisements contain emojis, with 465 postings including only one emoji, and 16 descriptions containing 17 or more emojis! The registered symbol ® (both emoji and unicode form) is the most frequently used, followed by the check mark ✅ and the rocket 🚀.
Figure 10: Most Frequent Emojis in Data Job Descriptions
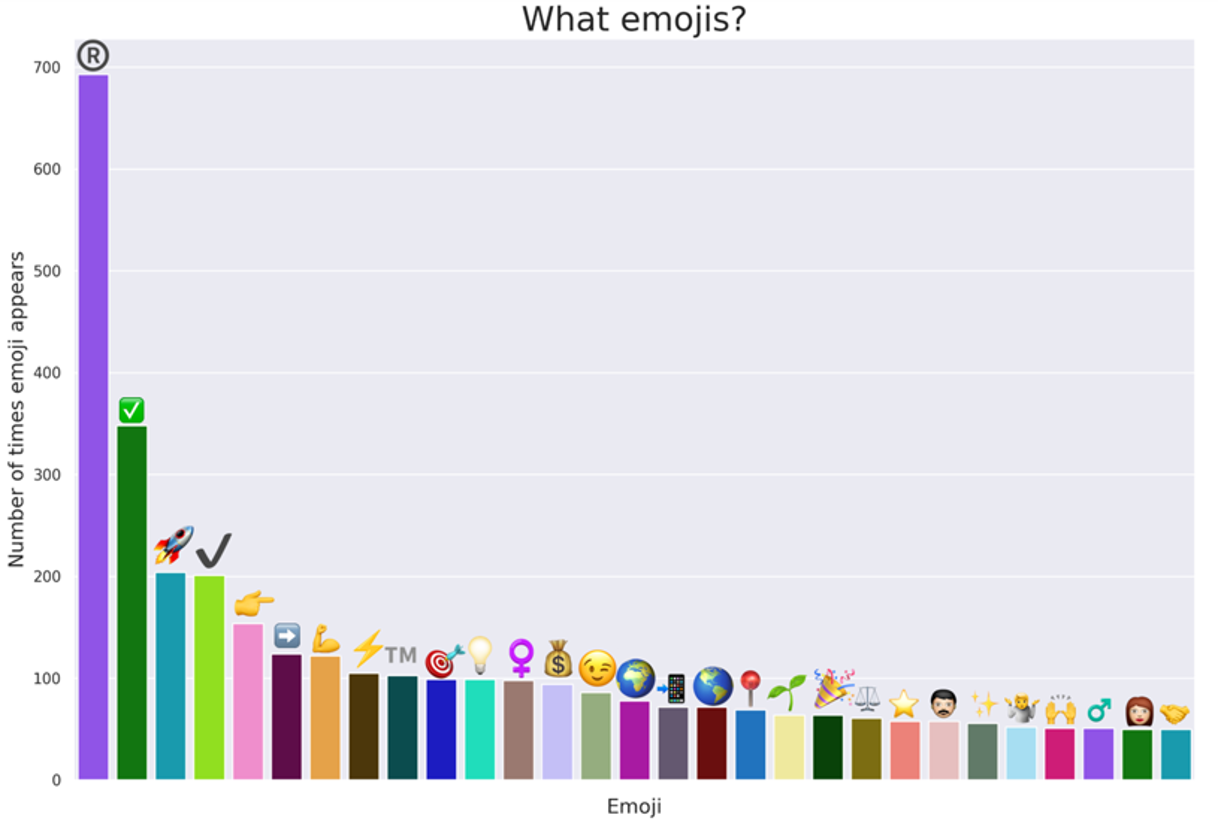
The registered symbol ® might be used to emphasize the authenticity or official status of the company, reflecting a sense of professionalism and legitimacy; the check mark ✅, often associated with completion or validation, could signify the fulfillment of certain criteria, thereby reassuring potential candidates that the position meets specific standards or qualifications; and the rocket 🚀, symbolizing growth, innovation, or a dynamic approach, could convey the company’s forward-thinking mindset, aspiration for growth, or enthusiasm for new ideas, making the job opportunity seem more exciting and progressive.
The Future of Data Analysis - Ask a Model!
The path to a successful data job can often feel like navigating a labyrinth. With nearly 26,000 data job descriptions posted in the first 4 months of this year (only in Belgium!), aspiring data scientists find themselves overwhelmed by an ocean of information.
AI Assistants Trying to Navigate Thousands of Data Job Descriptions. Credit: Jesse Blum via Midjourney

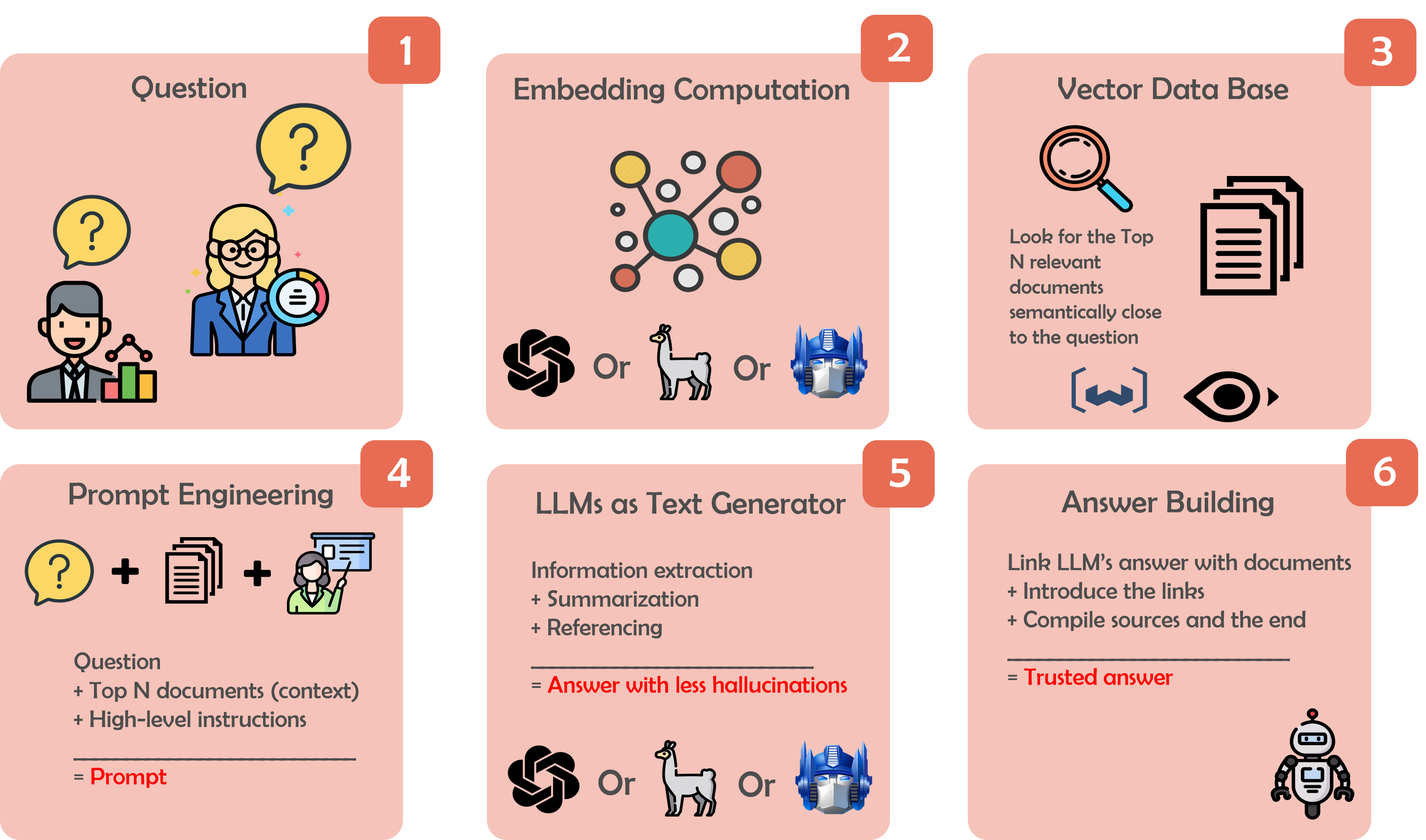
As a young data scientist, you do not have to fear, as the future of AI is here to change the game! Imagine having a personal AI assistant that accompanies you on your job search, simplifying the process, and illuminating the way to your ideal data role. The solution lies in an AI assistant powered by a RAG (Retrieval Augmented Generation) model, combining the best of both worlds: the search capabilities of a search engine and the interactive experience of a chatbot. Here’s how this approach works:
- The Question: Picture yourself as a curious job seeker, eager to explore the realm of data opportunities. Armed with your burning questions, you simply ask away.
- Question Transformation: The AI assistant springs into action, converting your questions into a document embedding (using OpenAI API)
- Semantic Similarity Search: with your question’s document embedding, the AI assistant conducts a semantic similarity search, sifting through a vast pool of job posts to find the N most relevant matches.
- Prompt Engineering: with the most pertinent job listings in hand, it’s time for some prompt engineering. By summoning the power of advanced generative models like GPT-4 or GPT-3, the solution uses a compelling and insightful prompt.
- Text Generation: As your questions reach the generative model or LLM (Large Language Model), the solution brings back comprehensive answers,
- Answer Building: with the text generation at hand, this is further enriched with relevant links and other artifacts.
The following video shows our AI assistant in action:

Summary and Conclusion
In summary, in this blog post, we describe the results of a data analysis of 25,965 job ads for the Belgian market returned for the query “data scientist” from a major online job board in the first four months of 2023.
We found that the most-frequently-returned job ads for the data scientist were not data science jobs! The most frequent job title by far was “software developer”, followed a distant second by “project manager”.
When focusing on data roles specifically, we found that the top three most common job titles were business analyst, devops engineer, and data engineer. The vast majority of the data job ads were posted by recruiting companies and IT consultancies. In 2023 in Belgium, the route to a data job passes much more through external companies than through direct hiring for internal roles (what consultancies typically call the “client-side”). There were many more roles at smaller companies than there were at larger organizations, and data professionals in the Belgian market are expected to be present at the office, either occasionally (through a hybrid work arrangement), or full-time.
Using insights provided by a chat GPT analysis of the job description text, we were able to examine which software tools and skills employers were looking for data roles. As in last year’s analysis, Python and SQL were the most-frequently mentioned tools. In contrast to last year, soft skills such as communication and stakeholder management appeared frequently in our analysis. In our view, this is encouraging, and suggests that employers are recognizing that a mix of technical and people skills are necessary to deliver successful data projects.
A simultaneous clustering of the software tools and data roles revealed how technologies and tasks that were previously the purview of data engineers (e.g. managing cloud infrastructure and deployment), are being split among newer up-and-coming roles (e.g. the cloud part usurped by the cloud engineers and the deployment part usurped by the devops engineers). This example serves as a nice illustration of the fast-pace of simultaneous evolution of technology and data job titles that characterizes the data space in 2023.
Finally, we uncovered a number of types of behaviors from prospective employers that job applicants should be aware of. Firstly, we saw that recruitment companies in particular often post the same job multiple times, likely to surge to the top of returned results on the job platform. We also found that some employers made somewhat gratuitous use of emoji’s in their job ads, presumably to appear “cool” to prospective applicants.
We hope you’ve found this analysis interesting and perhaps even useful. The data job market in Belgium in 2023 is vibrant and large, and our analysis should be encouraging to prospective data workers - there’s lots of opportunities out there - we hope you find a job that you love!
Data Scientists Find Professional Satisfaction. Credit: Jesse Blum via Midjourney
