Clustering Music Genres with R
In a number of upcoming posts, I’ll be analyzing an interesting dataset I found on Kaggle. The dataset contains information on 18,393 music reviews from the Pitchfork website. The data cover reviews posted between January 1999 and January 2016. I downloaded the data and did an extensive data munging exercise to turn the data into a tidy dataset for analysis (not described here, but perhaps in a future blog post).
The goal of this post is to describe the similarities and differences among the music genres of the reviewed albums using cluster analysis.
The Data
After data munging, I was left with 18,389 reviews for analysis (there were 4 identical review id’s in the dataset; visual inspection showed that the reviews were identical so I removed the duplicates).
One of the pieces of information about each album is the music genre, with the following options available: electronic, experimental, folk/country, global, jazz, metal, pop/rnb, rap and rock. Each album can have 0, 1 or multiple genres attached to it. I represented this information in the wide format, with one column to represent each genre. The presence of a given genre for a given album is represented with a 1, and the absence of a given genre for a given album is represented with a 0.
The head of the dataset, called “categories,” looks like this:
| title | artist | electronic | experimental | folk_country | global | jazz | metal | pop_rnb | rap | rock |
|---|---|---|---|---|---|---|---|---|---|---|
| mezzanine | massive attack | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| prelapsarian | krallice | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| all of them naturals | uranium club | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| first songs | kleenex liliput | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| new start | taso | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| insecure (music from the hbo original series) | various artists | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
As we can see, each album has numeric values on all of our 9 genres. The album in the last row of the data shown above does not have a genre attached to it.
Let’s first answer some basic questions about the music genres. How often is each genre represented in our 18,389 reviews? We can make a simple bar plot using base R with the following code:
# histogram of genre frequencies
par(mai=c(1,1.5,1,1))
barplot(sort(colSums(categories[,3:11]), decreasing = FALSE),
horiz = TRUE, cex.names = 1, col = 'springgreen4',
main = 'Genre Frequency', las = 1) Which gives us the following plot:
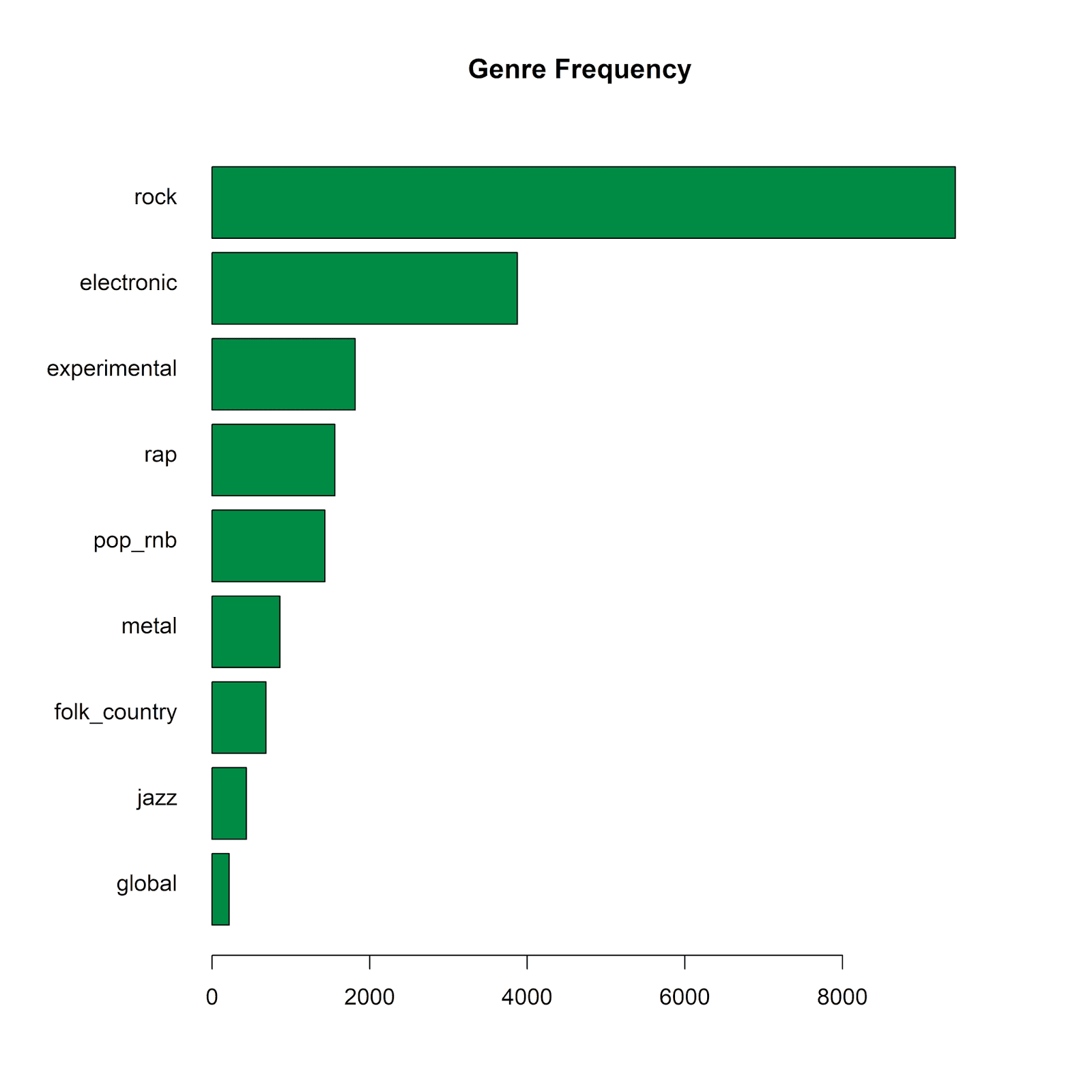
Rock is by far the most frequently-occurring genre in the dataset!
Let’s not forget that albums can have more than one genre. How many albums have more than 1 genre attached to them? What is the maximum number of genres in these data? What number of albums have what number of genres? It’s possible to extract these figures with dplyr, but for basic summary statistics I find it quicker and easier to use base R:
# how many of the albums have more than 1 genre?
table(rowSums(categories[,3:11])>1)
# FALSE TRUE
# 14512 3877
# what is the maximum number of genres?
max(rowSums(categories[,3:11]))
# [1] 4
# how many albums have what number of genres?
table(rowSums(categories[,3:11]))
# 0 1 2 3 4
# 2365 12147 3500 345 32 It looks like 3,877 of the albums have more than 1 genre. The table shows that the vast majority of albums with more than 1 genre have 2 genres, with a much smaller number having 3 and 4 genres. There are 2,365 albums with no recorded genre.
Data Preparation
In order to cluster the music genres, we first must make a matrix which contains the co-occurrences of our dummy-coded genre variables with one another. We can use matrix multiplication to accomplish this, as explained in this excellent StackOverflow answer:
# make a co-occurrence matrix
# select the relevant columns and convert to matrix format
library(plyr); library(dplyr)
co_occur <- categories %>% select(electronic, experimental, folk_country,
global,jazz, metal, pop_rnb, rap, rock) %>% as.matrix()
# calculate the co-occurrences of genres
out <- crossprod(co_occur)
# make the diagonals of the matrix into zeros
# (we won't count co-occurrences of a genre with itself)
diag(out) <- 0 The resulting co-occurrence matrix, called “out”, is a 9 by 9 matrix containing the counts of the genre co-occurrences together in the data:
| electronic | experimental | folk_country | global | jazz | metal | pop_rnb | rap | rock | |
|---|---|---|---|---|---|---|---|---|---|
| electronic | 0 | 198 | 26 | 49 | 127 | 40 | 228 | 81 | 1419 |
| experimental | 198 | 0 | 15 | 20 | 76 | 64 | 32 | 17 | 1121 |
| folk_country | 26 | 15 | 0 | 7 | 6 | 10 | 65 | 2 | 52 |
| global | 49 | 20 | 7 | 0 | 13 | 0 | 48 | 3 | 33 |
| jazz | 127 | 76 | 6 | 13 | 0 | 26 | 52 | 25 | 57 |
| metal | 40 | 64 | 10 | 0 | 26 | 0 | 12 | 27 | 449 |
| pop_rnb | 228 | 32 | 65 | 48 | 52 | 12 | 0 | 133 | 126 |
| rap | 81 | 17 | 2 | 3 | 25 | 27 | 133 | 0 | 68 |
| rock | 1419 | 1121 | 52 | 33 | 57 | 449 | 126 | 68 | 0 |
Cluster Analysis
We can now proceed with the cluster analysis. We will use hierarchical clustering, an algorithm which seeks to build a hierarchy of clusters in the data. This analysis will produce groupings (e.g. clusters) of music genres. We will visualize the results of this analysis via a dendrogram.
We first need to produce a distance matrix from our co-occurrence matrix. For each pair of music genres, we will calculate the Euclidean distance between them. To calculate the Euclidean distances, we first calculate the sum of the squared differences in co-occurrences for each pair of rows across the nine columns. We then take the square root of the sum of squared differences. If we consider the two bottom rows (rap and rock) in the co-occurrence matrix above, then the Euclidean distance between them is calculated as follows:
# calculate Euclidean distance manually between rock and rap
squared_diffs = (81-1419)^2 + (17-1121)^2 + (2-52)^2 + (3-33)^2 +
(25-57)^2 + (27-449)^2 + (133-126)^2 + (0-68)^2 + (68-0)^2
sqrt(squared_diffs)
# [1] 1789.096 This calculation makes clear our definition of genre similarity, which will define our clustering solution: two genres are similar to one another if they have similar patterns of co-occurrence with the other genres.
Let’s calculate all pairwise Euclidean distances with the dist() function, and check our manual calculation with the one produced by dist().
# first produce a distance matrix
# from our co-occurrence matrix
dist_matrix <- dist(out)
# examine the distance matrix
round(dist_matrix,3)
# the result for rap+rock
# is 1789.096
# the same as we calculated above! As noted in the R syntax above (and shown in the bottom-right corner of the distance matrix below), the distance between rap and rock is 1789.096, the same value that we obtained from our manual calculation above!
The distance matrix:
| electronic | experimental | folk_country | global | jazz | metal | pop_rnb | rap | |
|---|---|---|---|---|---|---|---|---|
| experimental | 462.453 | |||||||
| folk_country | 1397.729 | 1087.241 | ||||||
| global | 1418.07 | 1102.418 | 38.105 | |||||
| jazz | 1392.189 | 1072.719 | 122.511 | 106.353 | ||||
| metal | 1012.169 | 698.688 | 405.326 | 420.86 | 405.608 | |||
| pop_rnb | 1346.851 | 1006.476 | 275.647 | 259.559 | 197.16 | 397.776 | ||
| rap | 1375.999 | 1066.633 | 92.644 | 101.975 | 116.816 | 406.478 | 259.854 | |
| rock | 2250.053 | 2041.001 | 1836.619 | 1818.557 | 1719.464 | 1854.881 | 1682.785 | 1789.096 |
To perform the clustering, we simply pass the distance matrix to our hierarchical clustering algorithm (specifying that we to use Ward’s method), and produce the dendrogram plot.1
# perform the hierarchical clustering
hc <- hclust(dist_matrix, method="ward.D")
# plot the dendrogram
plot(hc, hang=-1, xlab="", sub="") 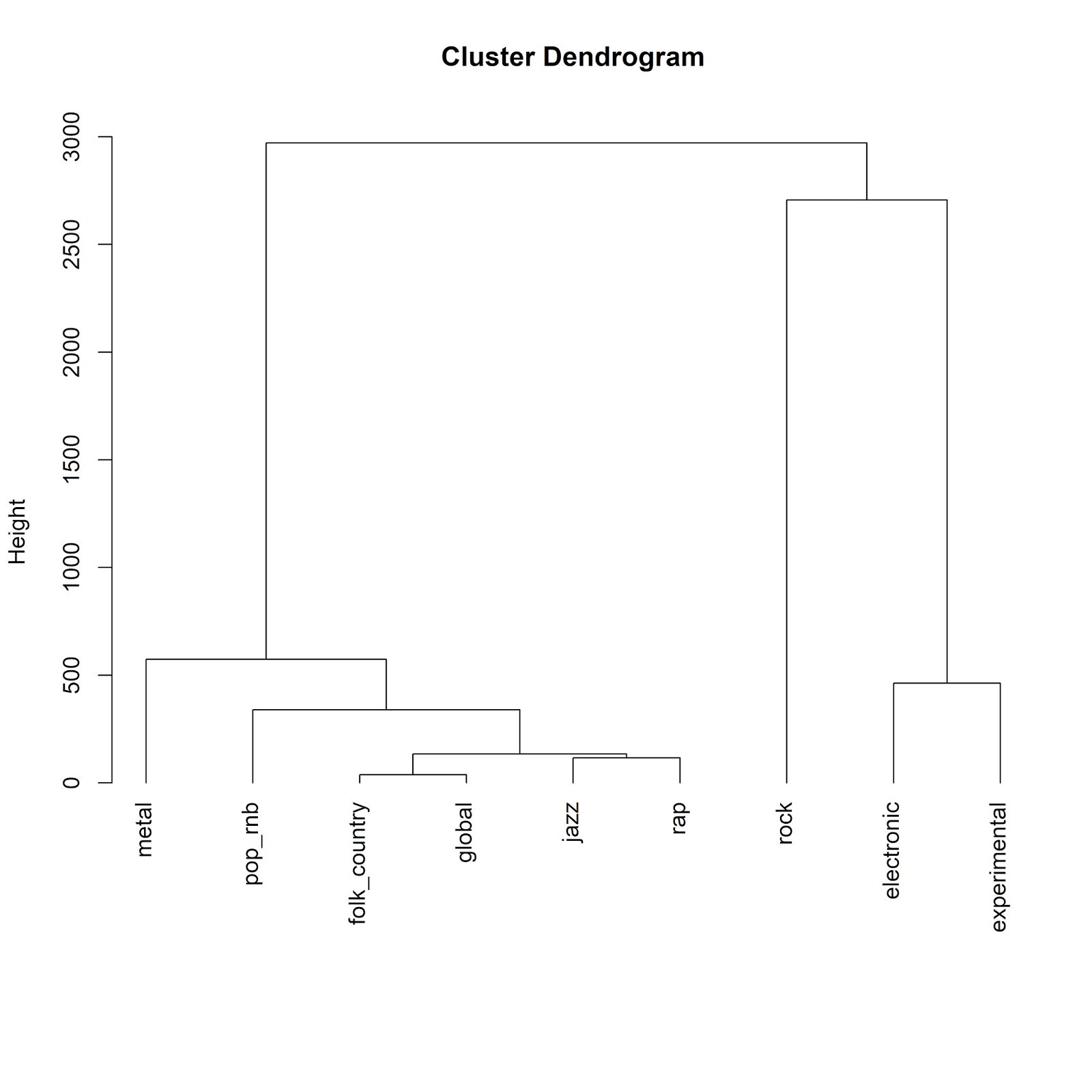
The hierarchical clustering algorithm produces the organization of the music genres visible in the above dendrogram. But how many clusters are appropriate for these data?
There are many different ways of choosing the number of clusters when performing cluster analysis. With hierarchical clustering, we can simply examine the dendrogram and make a decision about where to cut the tree to determine the number clusters for our solution. One of the key intuitions behind the dendrogram is that observations that fuse together higher up the tree (e.g. at the top of the plot) are more different from one another, while observations that fuse together further down (e.g. at the bottom of the plot) are more similar to one another. Therefore, the higher up we split the tree, the more different the music genres will be among the clusters.
If we split the tree near the top (e.g., around a height of 2500), we end up with three clusters. Let’s make a dendrogram that represents each of these three clusters with a different color. The colored dendrogram is useful in the interpretation of the cluster solution.
There are many different ways to produce a colored dendrogram in R; a lot of them are pretty hacky and require a fair amount of code. Below, I use the wonderful dendextend package to produce the colored dendrogram in a straightforward and simple way (with a little help from this StackOverflow answer):
# make a colored dendrogram with the dendextend package
library(dendextend)
# hc is the result of our hclust call above
dend <- hc
# specify we want to color the branches and labels
dend <- color_branches(dend, k = 3)
dend <- color_labels(dend, k = 3)
# plot the colored dendrogram. add a title and y-axis label
plot(dend, main = 'Cluster Dendrogram', ylab = 'Height') Which yields the following plot:
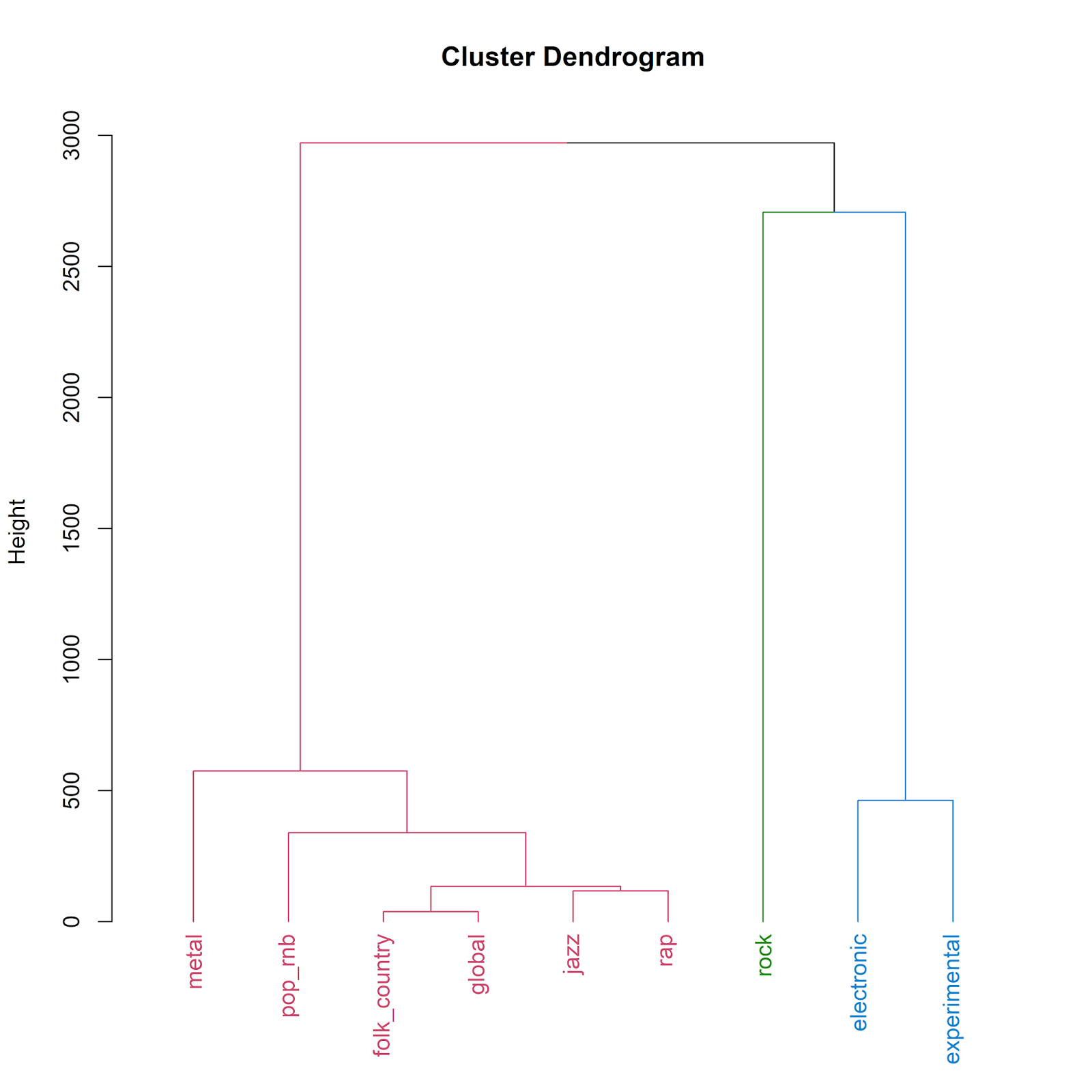
Interpretation of the Clusters
The Clusters
The three clusters identified by our chosen cut point are as follows. First, on the right-hand side of the plot, we see electronic and experimental music grouped together in a single cluster (colored in blue). Also on the right-hand of the plot, on the same branch but with a different leaf and colored in green, we find rock music which constitutes a cluster in and of itself. These two clusters (electronic + experimental and rock) are distinct, yet they share some similarities in terms of their co-occurrences with other music genres, as indicated by their fusion at the top right-hand side of the dendrogram.
On the left-hand side of the dendrogram, we see the third cluster (colored in pink) which encompasses metal, pop/r&b, folk/country, global, jazz *and *rap music. Our chosen cut point lumps all of these genres into a single cluster, but examination of the sub-divisions of this cluster reveals a more nuanced picture. Metal is most different from the other genres in this cluster. A further sub-grouping separates pop/r&b from folk/country, global, jazz and rap. Folk/country and global are fused at the lowest point in the dendrogram, followed by a similar grouping of jazz and rap. These two pairings occur very close to the bottom of the dendrogram, indicating strong similarity in genre co-occurrence between folk/country and global on the one hand, and between jazz and rap on the other hand.
Substantive Interpretation: What have we learned about music genres?
Rock (Green Cluster)
Rock music is the only music genre to get its own cluster, suggesting that it is distinctive in its patterns of co-occurrence with the other genres.
We must keep in mind the following statistical consideration, however. Rock music was the most frequent genre in the dataset. One of the reason rock’s Euclidean distances were so large is that, because this genre occurs so frequently in the data, the distances calculated between rock and the less-frequently occurring genres are naturally larger.
Electronic & Experimental (Blue Cluster)
The blue cluster in the dendrogram above groups electronic and experimental music together. One reason for this might be because these genres are both relatively more modern (compared to, say, jazz or folk), and therefore share some sonic similarities (for example, using electronic or synthetically generated sounds) which leads them to be used in a similar way in conjunction with the other music genres.
Metal, Pop/R&B, Folk/Country, Global, Jazz and Rap (Pink Cluster)
The remaining genres fall into a single cluster. Within this cluster, it seems natural that metal is most different from the other genres, and that pop/r&b separates itself from folk/country, global, jazz and rap.
Pop and R&B are different, in my vision, from folk/country, global, jazz and rap music in that the former feature slick production styles (e.g. a tremendously layered sound with many different tracks making up a song), electronic instrumentation (e.g. keyboard synthesizers and drum machines) and a contemporary musical aesthetic (e.g. auto-tuning to produce noticeably distorted vocals), whereas the latter feature more sparse arrangements and fewer electronically-produced sounds.
Folk/country and global music, meanwhile, share a similar musical palette in terms of their more traditional instrumentation. While there are exceptions, I feel that both folk/country and global music use more acoustic or “natural” instruments (guitars, violins, wind instruments, drums, etc.) and less of the obviously electronically-produced sounds mentioned above.
Finally, jazz and hip-hop, although quite different in many musical aspects, share a similar aesthetic in some ways. Hip-hop, for example, has long made use of samples from older records (including many jazz tunes) to create beats (although recent hip-hop sub-genres such as trap music make use of drum machines and synthesizers for a more mechanical sound). One testament to the complementary between jazz and rap are number of recent notable collaborations between artists in these two genres: Kendrick Lamar’s excellent 2015 album To Pimp a Butterfly contains a number of tracks featuring jazz musicians and jazz instrumentation, the jazz pianist Robert Glasper has made a several collaborative albums featuring rap artists, and the jazzy group BadBadNotGood made an excellent album with the always brilliant Ghostface Killah.
Conclusion
In this post, we clustered music genres from albums reviewed by Pitchfork. Our original dataset contained dummy-coded indicators for 9 different music genres across 18,389 different albums. We used matrix multiplication to create a co-occurrence matrix for the music genres, which we then turned into a distance matrix for hierarchical clustering. We cut the resulting dendrogram high up on the tree, obtaining three separate clusters of music genres: 1) rock 2) electronic and experimental and 3) metal, pop/r&b, folk/country, global, jazz and rap. This clustering solution seems to align with the production styles, sonic and musical qualities, and past and current cross-pollination between the various music genres.
Coming Up Next
In the next post, I’ll use R to produce a unique visualization of a very famous dataset. Stay tuned!
-
If you’re interested, you can play around with other distance metrics and clustering algorithms at home- just import the above co-occurrence matrix into R, and adapt the code however you like! ↩