A Tale of Two (Small Belgian) Cities with Open Data: Official Crime Statistics and Self-Reported Feelings of Safety in Leuven and Vilvoorde
In this post, we will analyze government data from the Flemish region in Belgium on A) official crime statistics and B) self-reported feelings of safety among residents of Flanders. We will focus our analysis on two cities in the province of Flemish Brabant: Leuven and Vilvoorde. A key question of this analysis is: do the residents of the safer city (as measured by official government statistics) feel safer and have more pride in their city (according to government polling data)?
The Data
Crime
Our first set of data consists of official crime figures from the Flemish government, obtained at this website. I chose to download the data adjusted for population size. Specifically, the data record the number of reported incidents per 1000 residents. The types of crime reported are: property damage, theft, physical violence, and overall incidents. As of October 2018, these figures were available for the years 2000-2016.
Subjective Feelings About the Cities
The Flemish government regularly conducts a survey (called the “Stadsmonitor”) to monitor how the residents of Flanders feel about many different topics, including how people feel about the city or town where they live. Summary data are available by question on the official survey website. In this blog post, we will analyze answers from 2017 on the following questions: insecurity, problems, vandalism and pride in one’s city
Open Data and Code
I’m increasingly sharing data and code for blog posts in the hopes that this will be interesting or useful for readers. If you’d like to reproduce the analyses done here (or explore a different question), you can find the data and code at this link.
Data Preparation
Crime Data
The code below reads the raw crime data file and first does some basic cleaning. These files were only available in an Excel format, and were not meant to be machine readable, so it takes some effort to manipulate the data to work with them in statistical analysis programs like R.
I then produce an additional set of crime statistics for Leuven. Because Leuven is a university city, there are a number of students who live here during the year, but who are not officially registered as residents of the city. Essentially, these “invisible” residents live in the city, potentially commit or are victims of crime, but are not counted as residents and so do not factor into the calculation of crime per 1000 residents. In my analysis below, I’m assuming that there are an additional 30% “invisible” residents, and therefore divide all of the crime figures by 1.3. I call these data “Leuven student assumptions” because they are adjustments to the actual figures, and not the official statistics themselves. The 30% figure comes from this article (in Dutch), in which the former mayor gives an estimate of the number of “invisible” student residents.1
I then convert the data from its original wide format to a long format, as ggplot2 requires data in the long format for plotting. The code to read the data, produce the adjustment for students, and transform the data is below:
# load the packages we'll need
library(openxlsx)
library(ggplot2)
library(plyr);library(dplyr)
library(tidyr)
# install devtool version of package
# devtools::install_github("jbryer/likert")
library(likert)
# define path to the data
in_dir <- 'C:\\Folder\\'
# function to read in crime data
read_crime_data <- function(file_name_f, in_dir_f){
# read the Excel file
crime_raw_f <- read.xlsx(paste0(in_dir_f, file_name_f))
# remove weird rows with no data
crime_raw_f <- crime_raw_f[1:12,]
# make the column name city (translate from Dutch to English)
names(crime_raw_f)[names(crime_raw_f) == 'Gebied'] <- 'City'
# make the Flemish region code also in English
crime_raw_f$City[crime_raw_f$City == "Vlaams Gewest"] <- "Vlaams Gewest (Flemish Region)"
return(crime_raw_f)
}
# read in crime data
crime_clean <- read_crime_data('Leuven Vilvoorde Crime per 1000 inhabitants clean.xlsx',
in_dir)
# make function to adjust for
# "missing" students
# living but not registered in Leuven
divide_it <- function(x){
divided_figure <- x / 1.3
return(divided_figure)
}
# create the data for the Leuven student assumptions
leuven_w_students <- crime_clean %>% filter(City == 'Leuven') %>%
# mutate variables in the year columns (crime figures)
# we apply our function to each cell (divide by 1.3)
mutate_at(vars(`2000`:`2016`), divide_it) %>%
# change the name of the city to indicate it
# reflects our assumptions, not the actual data
mutate(City = dplyr::recode(City, 'Leuven' =
'Leuven Student Assumptions' ))
# stack our newly created data on top of original data
master_crime <- rbind(crime_clean, leuven_w_students)
# transform from wide to long format
# ggplot2 needs data in this structure
crime_long <- gather(master_crime, year, value, `2000`:`2016`) The code produces a dataset ( crime_long ) that looks like this (only first 10 lines shown):
| City | Categorie | year | value | |
|---|---|---|---|---|
| 1 | Leuven | Beschadigen van eigendom (aantal per 1.000 inw.) | 2000 | 14.82 |
| 2 | Leuven | Diefstal en afpersing (aantal per 1.000 inw.) | 2000 | 54.43 |
| 3 | Leuven | Misdr. tegen de lichamelijke integriteit (aantal per 1.000 inw.) | 2000 | 6.17 |
| 4 | Leuven | Criminaliteitsgraad (aantal per 1.000 inw.) | 2000 | 132.81 |
| 5 | Vilvoorde | Beschadigen van eigendom (aantal per 1.000 inw.) | 2000 | 8.47 |
| 6 | Vilvoorde | Diefstal en afpersing (aantal per 1.000 inw.) | 2000 | 44.95 |
| 7 | Vilvoorde | Misdr. tegen de lichamelijke integriteit (aantal per 1.000 inw.) | 2000 | 6.08 |
| 8 | Vilvoorde | Criminaliteitsgraad (aantal per 1.000 inw.) | 2000 | 88.22 |
| 9 | Vlaams Gewest (Flemish Region) | Beschadigen van eigendom (aantal per 1.000 inw.) | 2000 | 9.36 |
| 10 | Vlaams Gewest (Flemish Region) | Diefstal en afpersing (aantal per 1.000 inw.) | 2000 | 37.12 |
Note that we also have data on the entire Flemish region ( Vlaams Gewest ) which is a nice point of comparison - the global average across the territory. The descriptions are all in Dutch, but we’ll use English translations for plotting below.
Survey Data
The code below reads in the datasets (there is 1 dataset per question, and each dataset contains summary statistics from many different cities - here we focus on just Leuven and Vilvoorde). Unfortunately, there are slight differences in the formatting of the files between the questions, so I wrote a different function to read in every dataset. The functions read the data, select the observations from Leuven and Vilvoorde in 2017, and make English language column names (the original names are all in Dutch).
###### safety
read_safety_data <- function(file_name_f, in_dir_f){
# read the file, specifying that there are dates
safety_raw_f <- read.xlsx(paste0(in_dir, file_name_f), detectDates = TRUE)
# remove info hanging around at bottom of file
safety_raw_f <- safety_raw_f[!is.na(safety_raw_f$Indicator),]
# name the columns
names(safety_raw_f) <- c("Gemeente","Indicator","Item", 'Date', 'Empty',
'Never/Seldom', 'Sometimes', 'Often/Always')
# select observations just from 2017 - we only have Vilvoorde for that date
safety_raw_f <- safety_raw_f[safety_raw_f$Date == '2017-01-01',]
# remove the empty column
safety_raw_f$Empty <- NULL
# replace missings in questionnaire data with zeros
safety_raw_f[is.na(safety_raw_f)] <- 0
# select only relevant columns for Leuven and Vilvoorde
safety_raw_f <- safety_raw_f[safety_raw_f$Gemeente == 'Leuven' |
safety_raw_f$Gemeente == 'Vilvoorde',c(1,3,5:7)]
# make sure that the "Item" variable represents city vs. neighborhood
# (for Likert plot)
safety_raw_f$Item <- c('Neighborhood', 'City','Neighborhood', 'City')
# make city and Item factors
# (for Likert plot)
safety_raw_f$Gemeente <- as.factor(safety_raw_f$Gemeente)
safety_raw_f$Item <- as.factor(safety_raw_f$Item)
# return the clean dataset
return(safety_raw_f)
}
###### problems
read_problem_data <- function(file_name_f, in_dir_f){
# read the file, specifying that there are dates
probs_raw_f <- read.xlsx(paste0(in_dir, file_name_f), detectDates = TRUE)
# remove info hanging around at bottom of file
probs_raw_f <- probs_raw_f[!is.na(probs_raw_f$Indicator),]
# name the columns
names(probs_raw_f) <- c("Gemeente","Indicator","Item", 'Date', 'Empty',
'Never/Seldom', 'Sometimes', 'Often/Always')
# select observations just from 2017 - we only have Vilvoorde for that date
probs_raw_f <- probs_raw_f[probs_raw_f$Date == '2017-01-01',]
# remove the empty column
probs_raw_f$Empty <- NULL
# replace missings in questionnaire data with zeros
probs_raw_f[is.na(probs_raw_f)] <- 0
# select only relevant columns for Leuven and Vilvoorde
probs_raw_f <- probs_raw_f[probs_raw_f$Gemeente == 'Leuven' |
probs_raw_f$Gemeente == 'Vilvoorde',c(1,3,5:7)]
# delete the original item column (this is text on y axis)
probs_raw_f$Item <- NULL
# make city (Gemeente) the "Item"
# (for Likert plot)
names(probs_raw_f)[1] <- 'Item'
# return the clean dataset
return(probs_raw_f)
}
####### vandalism
read_vandalism_data <- function(file_name_f, in_dir_f){
# read the file, specifying that there are dates
vand_raw_f <- read.xlsx(paste0(in_dir, file_name_f), detectDates = TRUE)
# remove info hanging around at bottom of file
vand_raw_f <- vand_raw_f[!is.na(vand_raw_f$Indicator),]
# name the columns
names(vand_raw_f) <- c("Gemeente","Indicator","Item", 'Date', 'Empty',
'Never/Seldom', 'Sometimes', 'Often/Always')
# select observations just from 2017 - we only have Vilvoorde for that date
vand_raw_f <- vand_raw_f[vand_raw_f$Date == '2017' &
vand_raw_f$Item == 'Vernieling straatmeubilair',]
# remove the empty column
vand_raw_f$Empty <- NULL
# replace missings in questionnaire data with zeros
vand_raw_f[is.na(vand_raw_f)] <- 0
# select only relevant columns for Leuven and Vilvoorde
vand_raw_f <- vand_raw_f[vand_raw_f$Gemeente == 'Leuven' |
vand_raw_f$Gemeente == 'Vilvoorde',c(1,3,5:7)]
# delete the original item column (this is text on y axis)
vand_raw_f$Item <- NULL
# make city (Gemeente) the "Item"
# (for Likert plot)
names(vand_raw_f)[1] <- 'Item'
# return the clean dataset
return(vand_raw_f)
}
######### pride in one's city
read_pride_data <- function(file_name_f, in_dir_f){
# read the file, specifying that there are dates
pride_raw_f <- read.xlsx(paste0(in_dir, file_name_f), detectDates = TRUE)
# remove info hanging around at bottom of file
pride_raw_f <- pride_raw_f[!is.na(pride_raw_f$Indicator),]
# name the columns
names(pride_raw_f) <- c("Gemeente","Indicator","Item", 'Date', 'Empty',
'Mostly/Completely disagree',
'Neither agree nor disagree', 'Mostly/Completely agree')
# select observations just from 2017 - we only have Vilvoorde for that date
pride_raw_f <- pride_raw_f[pride_raw_f$Date == '2017-01-01',]
# remove the empty column
pride_raw_f$Empty <- NULL
# replace missings in questionnaire data with zeros
pride_raw_f[is.na(pride_raw_f)] <- 0
# select only relevant columns for Leuven and Vilvoorde
pride_raw_f <- pride_raw_f[pride_raw_f$Gemeente == 'Leuven' |
pride_raw_f$Gemeente == 'Vilvoorde',c(1,3,5:7)]
# delete the original item column (this is text on y axis)
pride_raw_f$Item <- NULL
# make city (Gemeente) the "Item"
# (for Likert plot)
names(pride_raw_f)[1] <- 'Item'
# return the clean dataset
return(pride_raw_f)
}
# read in the data
safety_clean <- read_safety_data('SAMEN_onveiligheid.xlsx', in_dir)
probs_clean <- read_problem_data('SAMEN_problemen.xlsx', in_dir)
vandal_clean <- read_vandalism_data('SAMEN_vandalisme.xlsx', in_dir)
pride_clean <- read_pride_data('WON_fierheid.xlsx', in_dir) Our functions are all executed in a single line, and return a cleaned dataset for each of the four questions we will examine.
For illustrative purposes, the safety dataset is shown below. The answers are in response to the following question: How often do you feel unsafe in your neighborhood and city?
| Gemeente | Item | Never/Seldom | Sometimes | Often/Always | |
|---|---|---|---|---|---|
| 1 | Leuven | Neighborhood | 83.79 | 13.16 | 3.05 |
| 2 | Leuven | City | 74.76 | 20.88 | 4.36 |
| 3 | Vilvoorde | Neighborhood | 66.04 | 24.05 | 9.91 |
| 4 | Vilvoorde | City | 46.67 | 31.22 | 22.11 |
Visualization
Crime Data
We will produce one graph for each outcome, and assemble the graphs into a single plot. For each outcome, we will plot four different lines, displaying the crime figures across the years for Leuven (“Leuven” in the plots below), Leuven with our assumptions about the student population (assuming 30% “invisible” student residents as described above, “Leuven Student Assumptions” in the plots below), Vilvoorde, and the Vlaams Gewest (average for the entire Flemish region).
The code below stores each single graph in an object, and uses the gridExtra package to plot them all in a single plot.
The code looks like this:
# property damage
prop_damage_plot <- crime_long %>%
filter(Categorie == 'Beschadigen van eigendom (aantal per 1.000 inw.)') %>%
ggplot(aes(x = year, y = value, color = City, group = City)) +
geom_line(aes(color = City), size = 1) +
geom_point() +
labs(x = 'Year', y = 'Property Damage (per 1000 inhabitants)',
title = 'Property Damage: 2000 - 2016')
# theft
theft_plot <- crime_long %>%
filter(Categorie == 'Diefstal en afpersing (aantal per 1.000 inw.)') %>%
ggplot(aes(x = year, y = value, color = City, group = City)) +
geom_line(aes(color = City), size = 1) +
geom_point() +
labs(x = 'Year', y = 'Theft (per 1000 inhabitants)',
title = 'Theft: 2000 - 2016')
# physical violence
phys_violence_plot <- crime_long %>%
filter(Categorie == 'Misdr. tegen de lichamelijke integriteit (aantal per 1.000 inw.)') %>%
ggplot(aes(x = year, y = value, color = City, group = City)) +
geom_line(aes(color = City), size = 1) +
geom_point() +
labs(x = 'Year', y = 'Physical Violence (per 1000 inhabitants)',
title = 'Physical Violence: 2000 - 2016')
# overall crime
overall_crime_plot <- crime_long %>%
filter(Categorie == 'Criminaliteitsgraad (aantal per 1.000 inw.)') %>%
ggplot(aes(x = year, y = value, color = City, group = City)) +
geom_line(aes(color = City), size = 1) +
geom_point() +
labs(x = 'Year', y = 'Overall Crime (per 1000 inhabitants)',
title = 'Overall Crime: 2000 - 2016')
# plot multiple graphs with grid.arrange
# from gridExtra package
# we give a bit of extra space at the bottom
# of each graph
library(gridExtra)
margin = theme(plot.margin = unit(c(1,.5,.5,.5), "cm"))
grid.arrange(grobs = lapply(list(prop_damage_plot, theft_plot, phys_violence_plot,
overall_crime_plot), "+", margin), nrow = 4) Which produces the following plot:
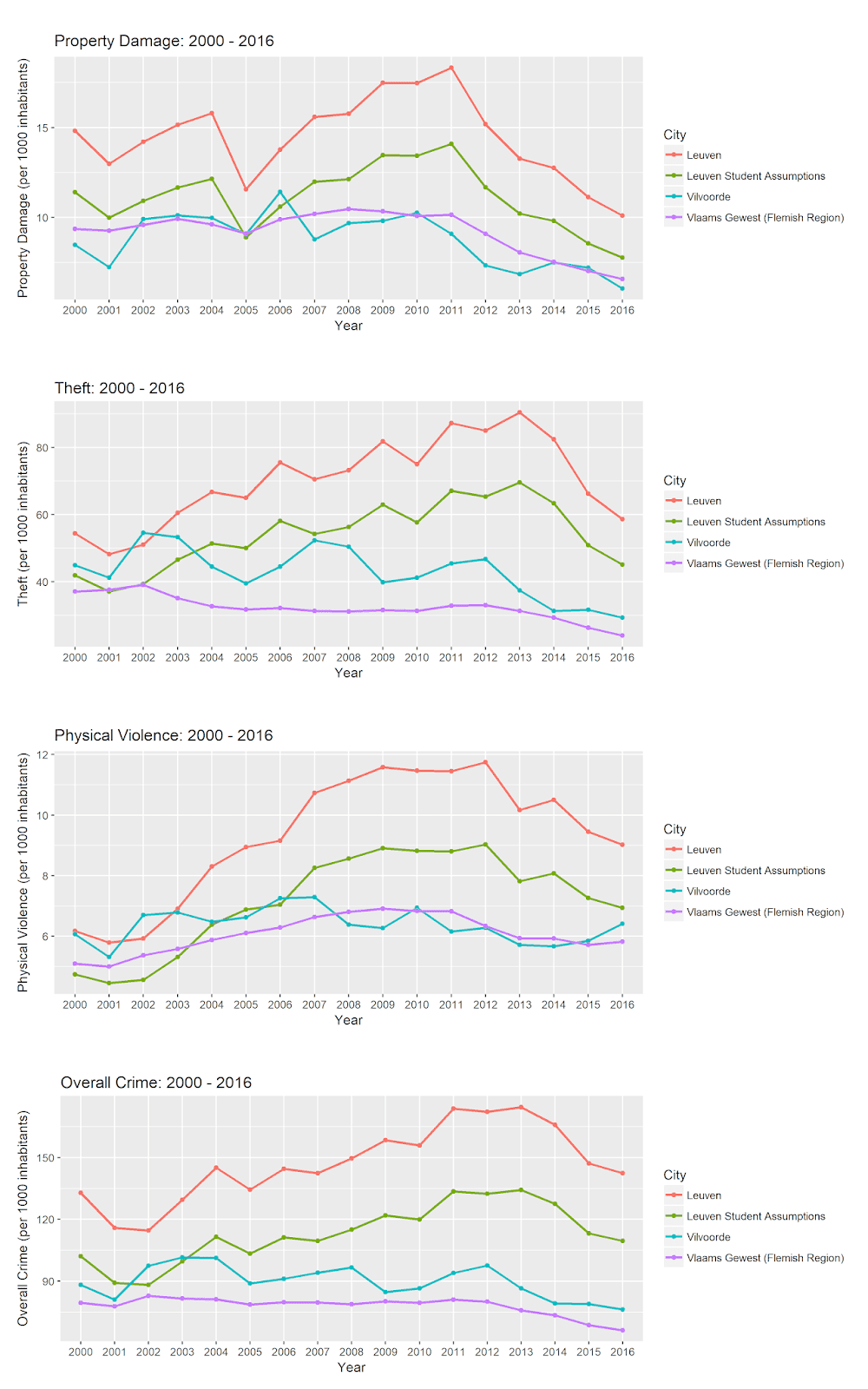
The official crime statistics for Leuven are higher than the other points of comparison for every outcome after 2003. Even with our assumptions about the “invisible” residents, Leuven consistently has higher crime rates than Vilvoorde and the Flemish region average. Vilvoorde sticks close to the Flemish average for property damage and physical violence, but is higher than average for theft and overall crime rates.
Questionnaire / Self-Report Data
Subjective Feelings of Safety
We will first take a look at subjective feelings of safety in one’s city and neighborhood. We will use the likert package to plot the responses to the questionnaires. The Likert package is great for producing stacked bar charts, a common visualization of responses to questionnaire data. The format of the data from the Stadsmonitor is also suited to this type of visual representation.
We first create a Likert scale object from the safety dataset we created above. Because the same question was asked in regard to both one’s neighborhood and one’s city, we will use a grouping in our plot. This will allow us to display the responses to both areas with a correct sub-heading for both neighborhood and city.
The code below creates the Likert object and produces the plot.
# make likert object
# for safety we use a grouping: neighborhood vs. city
# (questions were asked about both)
safety_likert <- likert(summary = safety_clean, grouping = safety_clean[,1])
# make the plot
plot(safety_likert, group.order = c('Leuven', 'Vilvoorde')) +
ggtitle('How often do you feel unsafe in your...') 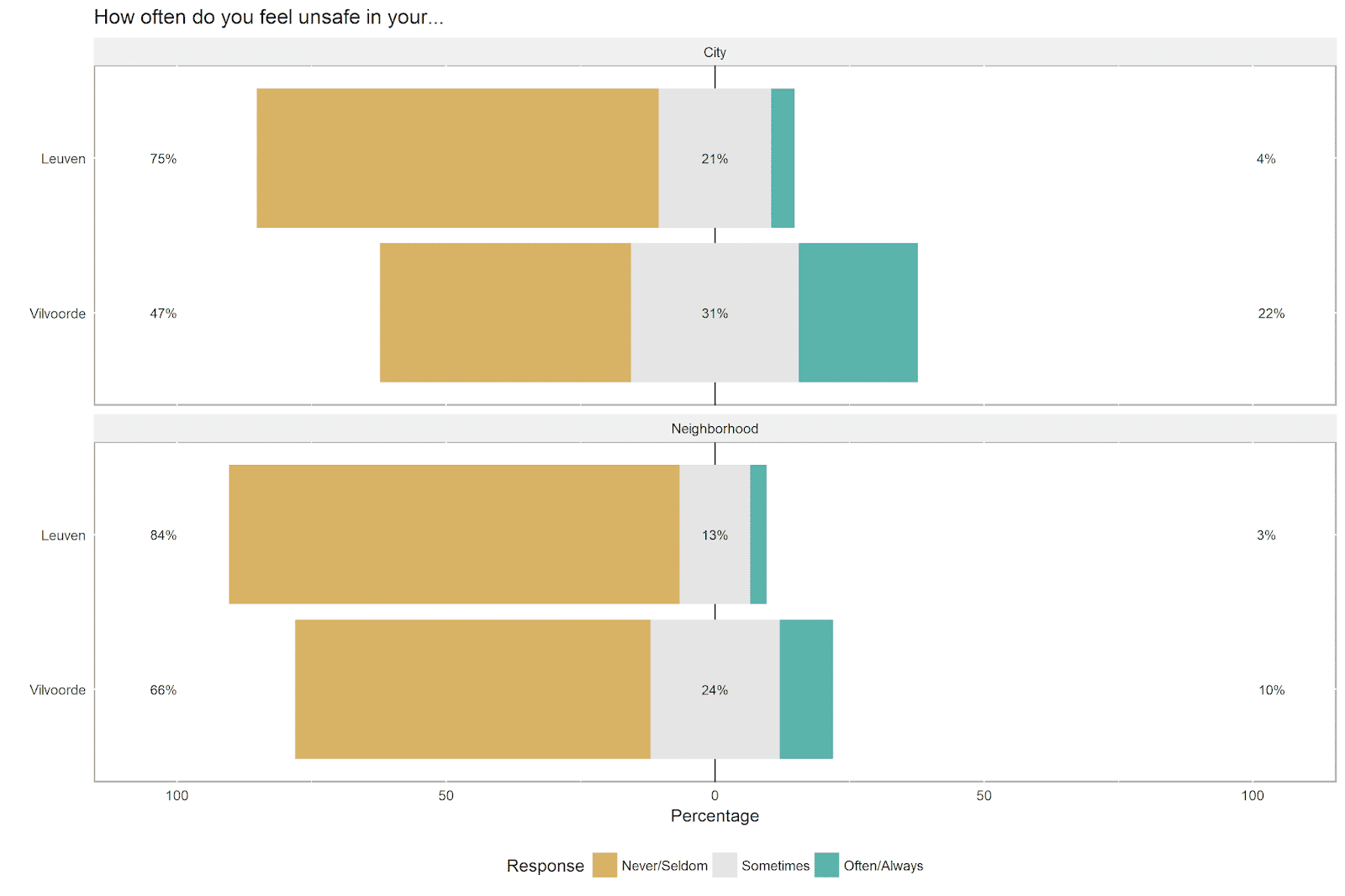
Leuven respondents rarely report feeling unsafe in their city (only 4% say they feel unsafe always or often ) and neighborhood (only 3%). The figures are considerably higher for Vilvoorde. Fully 22% of respondents in Vilvoorde say that they always or often feel unsafe in their city, and 10% say that they always or often feel unsafe in their neighborhood.
Social Problems and Pride in One’s City
We will next examine questions about two social problems: being hassled on the street and seeing vandalism (literally “witnessing the destruction of street furniture” - public benches, lamp posts, etc.). We will also look at reports of feelings of pride in one’s city (an overall perception which is no doubt informed by feelings of safety).
We will display these three questions in a single plot, as we did above for the crime data. We first create a Likert graph object for each question (as the questions don’t have the same question structure and response options, it’s better to plot each one by itself). We then use the gridExtra package to display all of the graphs in a single plot.
The following code creates the Likert graph objects and displays them in one large plot.
# make likert objects for the other questions
likert_problems <- likert(summary = probs_clean)
likert_vand <- likert(summary = vandal_clean)
likert_pride <- likert(summary = pride_clean)
# first make object for each graph
prob_plot <- plot(likert_problems, group.order = c('Leuven', 'Vilvoorde')) +
ggtitle('How often are you hassled on the street?')
vand_plot <- plot(likert_vand, group.order = c('Leuven', 'Vilvoorde')) +
ggtitle('How often do you see destruction of street furniture?')
pride_plot <- plot(likert_pride, group.order = c('Leuven', 'Vilvoorde')) +
ggtitle('I am truly proud of my city')
# plot multiple graphs with grid.arrange
# from gridExtra package
# we give a bit of extra space at the bottom
# of each graph
margin = theme(plot.margin = unit(c(1,.5,.5,.5), "cm"))
grid.arrange(grobs = lapply(list(prob_plot, vand_plot, pride_plot), "+", margin)) 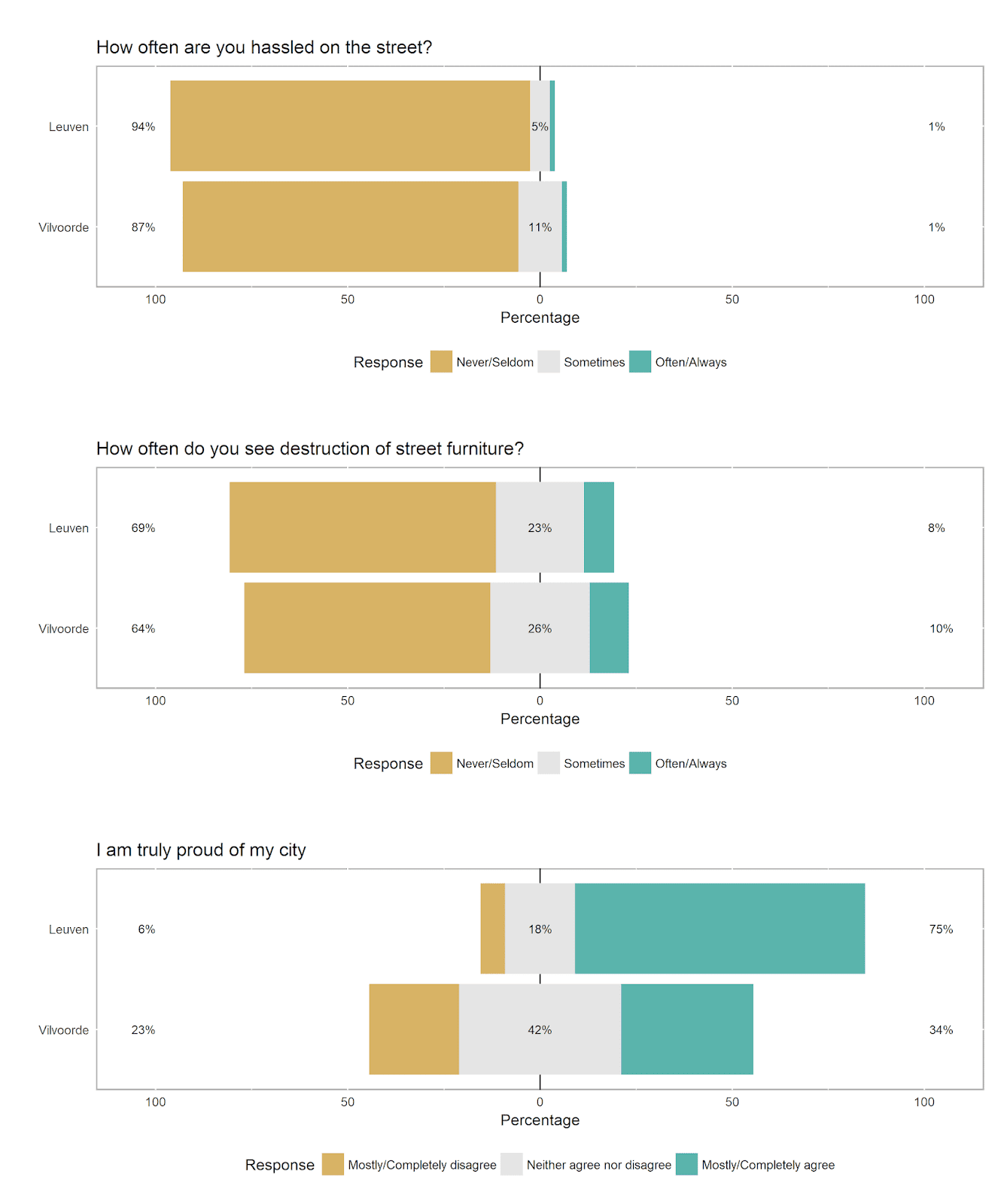
When considering the social problems questions (being hassled on the street and seeing vandalism), the percentage of respondents in Leuven and Vilvoorde who report that they often or always experience these things is more-or- less the same. The cities distinguish themselves in the middle and lower response categories. More residents in Vilvoorde (vs. Leuven) say that they sometimes are hassled on the street and witness vandalism, and fewer residents in Vilvoorde (vs. Leuven) say that they never or seldom experience these things. In sum, residents of Leuven report fewer social and safety-related problems than residents of Vilvoorde.
The results of the pride question are quite striking. In Leuven, 75% of the respondents are proud of their city versus only 34% in Vilvoorde (less than half the Leuven percentage). Only 6% of Leuven residents are not proud of their city, while this figure is 23% in Vilvoorde.
The self-report data are clear: residents of Leuven feel safer, report fewer social problems and are much more proud of their city when compared with residents of Vilvoorde.
Summary and Conclusion
In this post, we examined official crime statistics and survey data on subjective feelings of safety in two Flemish cities: Leuven and Vilvoorde. Interestingly, the official crime statistics and survey data seem to tell two different stories.
On the one hand, Leuven (compared to Vilvoorde) has considerably higher rates of property damage, theft and physical violence, even when assuming that the official statistics are slightly biased because of “invisible” students who are not legally registered as city residents.
On the other hand, people in Leuven say that they feel much safer in their neighborhoods and in their city. Residents of Leuven also report seeing fewer social problems and are prouder of their city.
It’s interesting to see this disconnect between official crime statistics and self-reported feelings of safety. I will admit that I’m not entirely sure what to make of this. Potential explanations for this disconnect include:
- There are more “invisible” student residents than I have assumed. If this is the case, it is possible that the true population-adjusted crime figures are lower in Leuven than in Vilvoorde (although to close the gap between the cities, there would have to be a very large number of invisible residents in Leuven).
- Residents in Vilvoorde under-report crime that happens in their city. If this is the case, the actual crime figures in Vilvoorde are much higher, perhaps equal to or greater than those in Leuven (although the similarity between the Vilvoorde figures and those of the Flemish region suggests this is unlikely).
- The “types” of people who respond to the survey questions are different in Leuven vs. Vilvoorde. If this is the case, the difference in observed feelings of safety and seeing social problems reflects sampling bias, not the true aggregate feelings of city residents. However, the Stadsmonitor survey appears to have been meticulously conducted, and it strikes me that such sampling errors are unlikely.
My sense of these data is that, in some contexts, actual safety and feelings of safety are different things. The overall crime figures in Leuven are not very high, even though they are much higher than the average for the Flemish region (which is, after all, a relatively well-off part of the world). Given the relatively low crime rate overall, perhaps other factors influence how residents feel in the place where they live.
Leuven is a wealthy city in a wealthy province. My sense is that people have a common identity as Leuven residents ( Leuvenaars in Dutch) and are in many ways a homogeneous group (despite a sizeable number of foreign students and academics). Furthermore, the city is doing well economically and has a vision for itself (the university, science and technology spinoffs, along with a large bank and brewery company are all valuable sources of revenue for the city and its residents and seem likely to ensure a solid future in the modern economy).
Vilvoorde, by comparison, is much less wealthy. It is socially very diverse, with its residents coming from many different parts of the world. As such, it doesn’t have a single strong source of identity like Leuven, and its diverse residents do not always mix or know each other very well.
Given the different economic and social situations of these two cities, it is perhaps understandable that Leuven residents feel safer than Vilvoorde residents, even when the actual crime statistics suggest that the opposite is true.
Coming Up Next
In the next post, we will solve a basic programming puzzle that is (apparently) asked in data-science interviews. We will use this puzzle as a case study for understanding similarities and differences in programming logic and implementation of control structures in R vs. Python.
Stay tuned!
-
If you’ve got a better one, please let me know in the comments! ↩